Kumari Preety, Singh Harendra Pal, Singh Swarn
Faculty of Mathematical Science, University of Delhi, Delhi, 110007 India.
School of Engineering & Technology, Central University of Haryana, Mahendergarh, 123031 India.
Appl Intell (Dordr). 2021;51(5):2818-2837. doi: 10.1007/s10489-020-01929-4. Epub 2020 Nov 13.
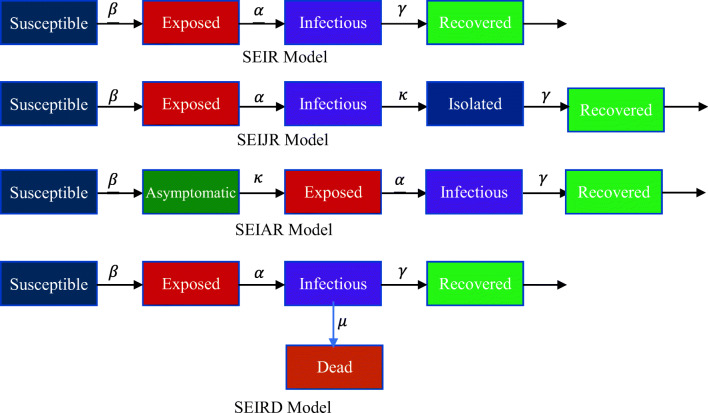
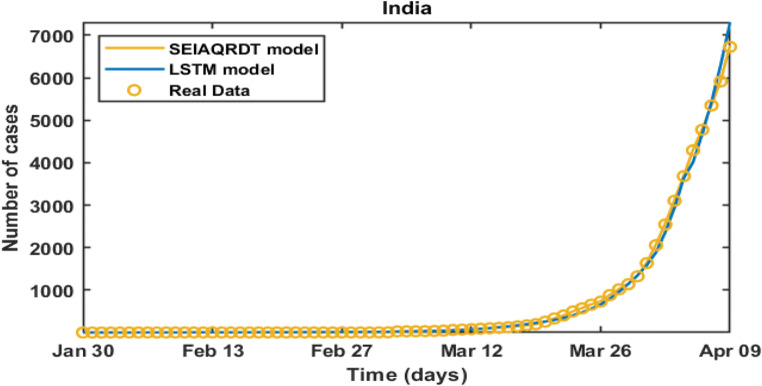
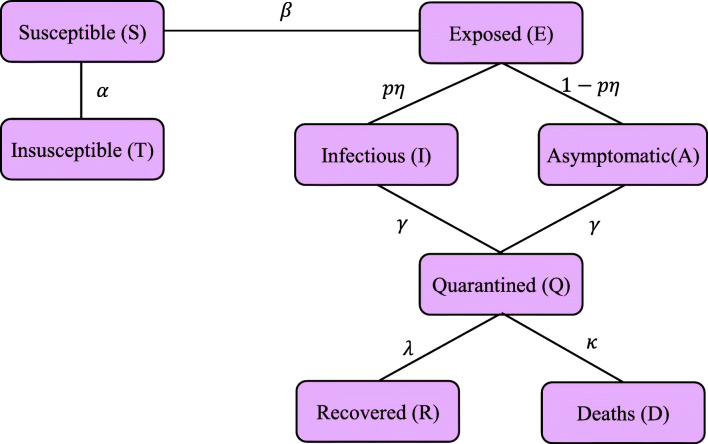
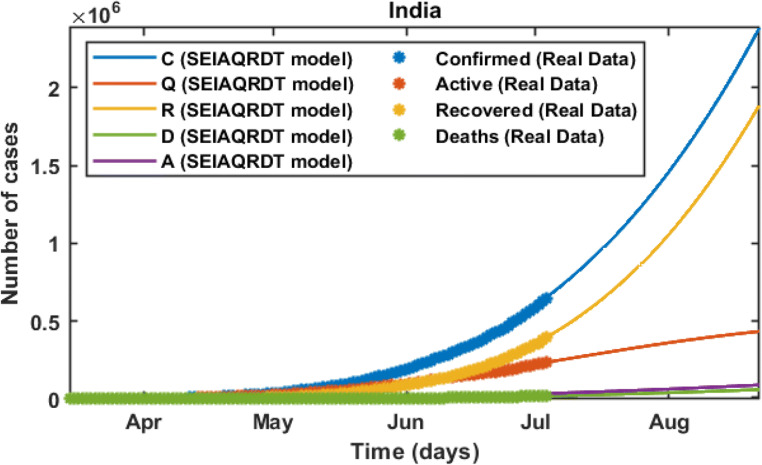
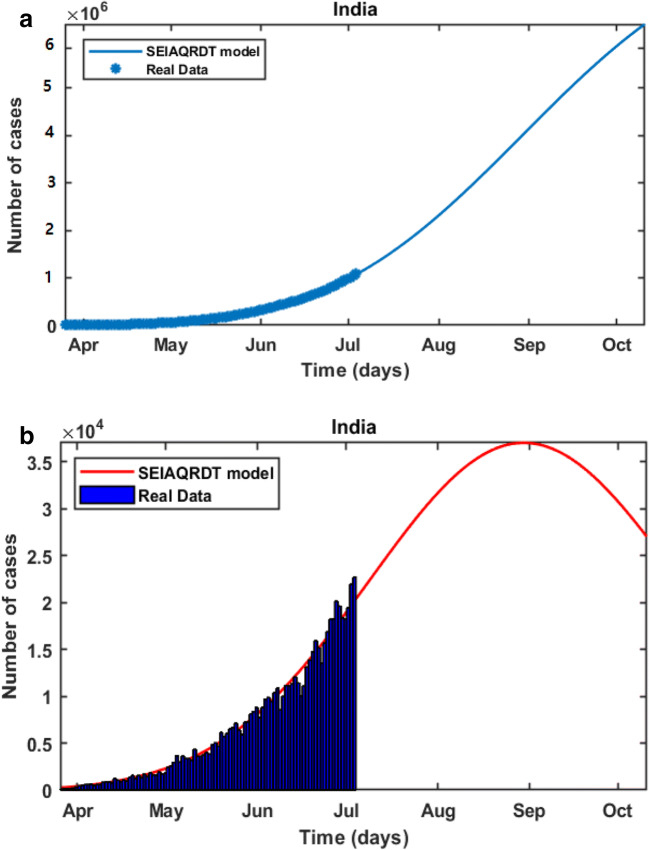
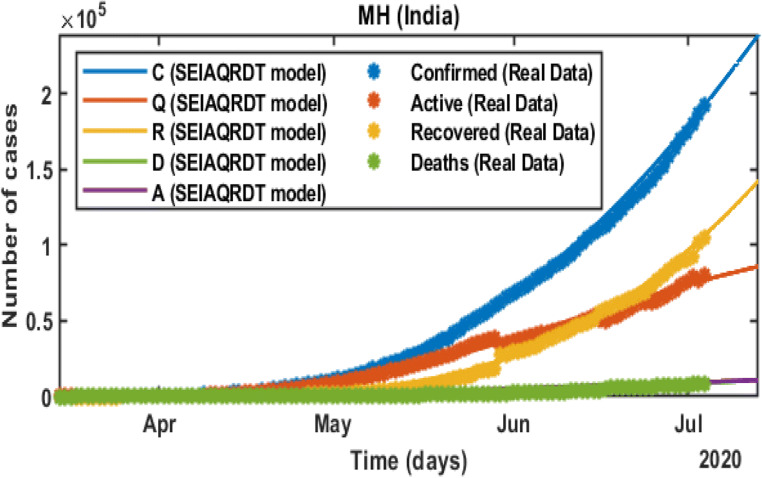
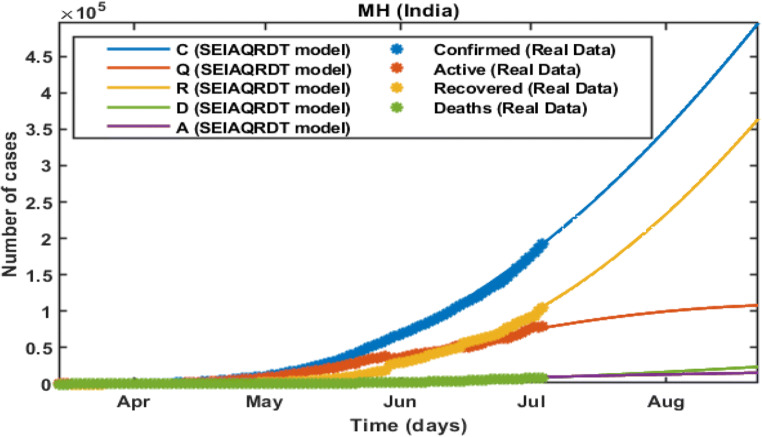
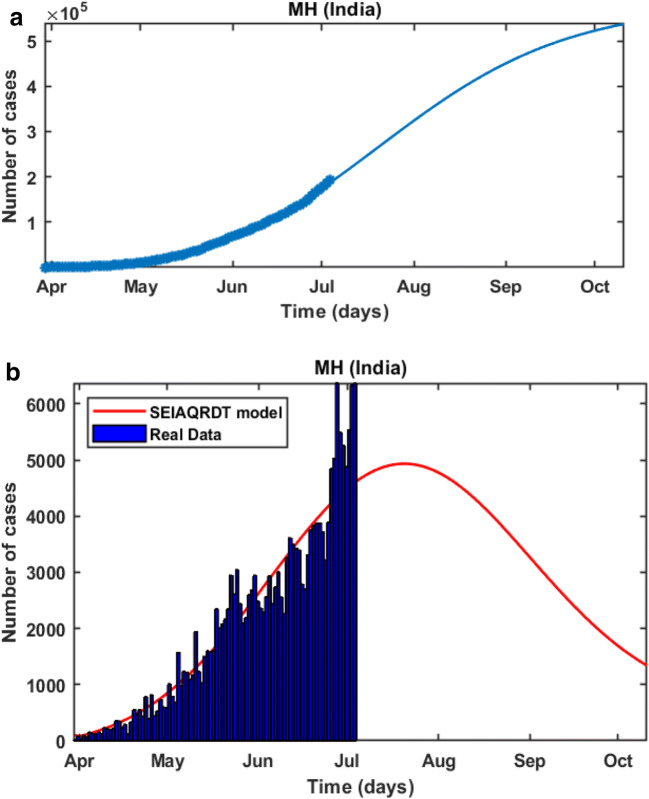
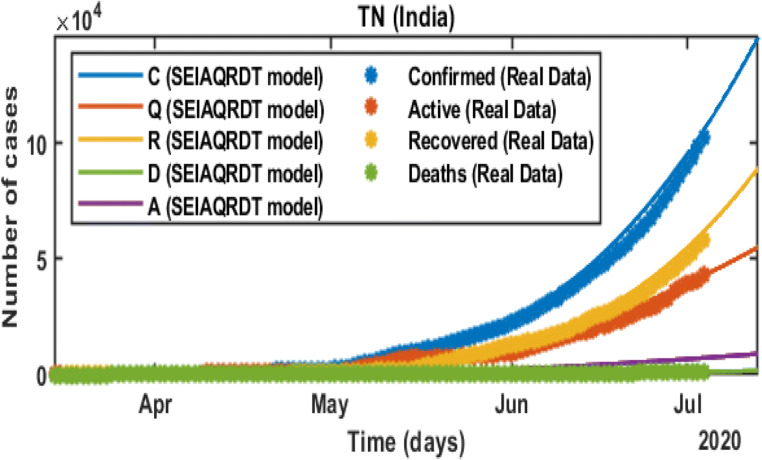
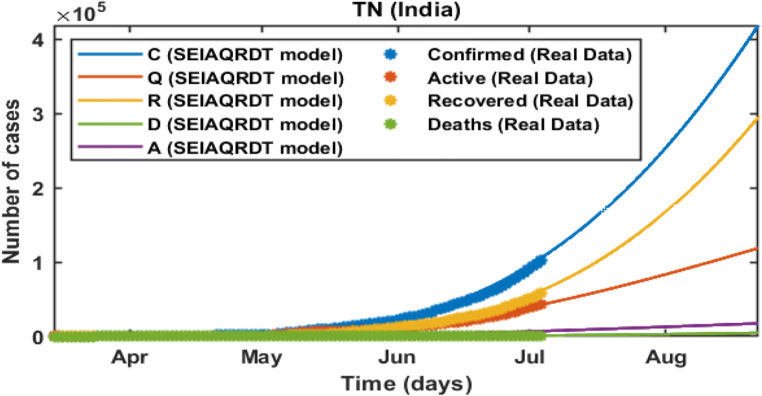
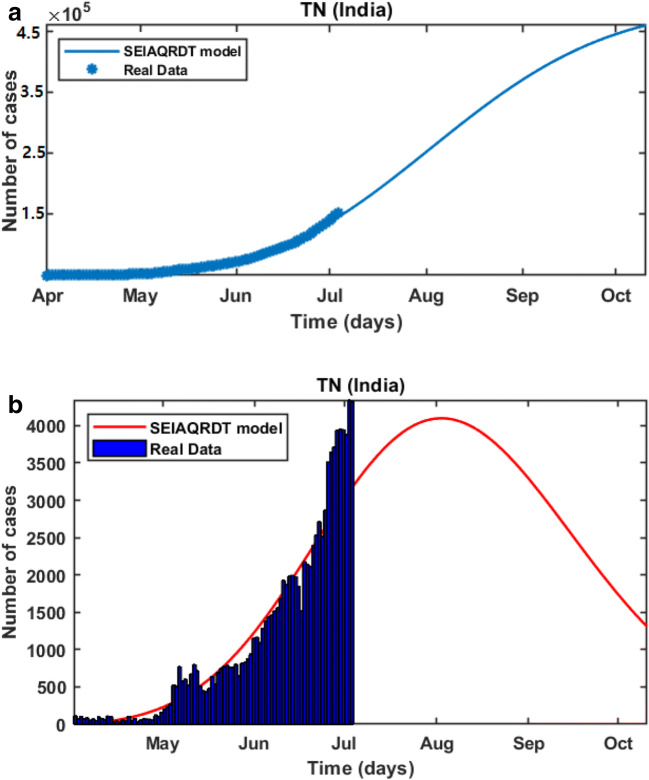
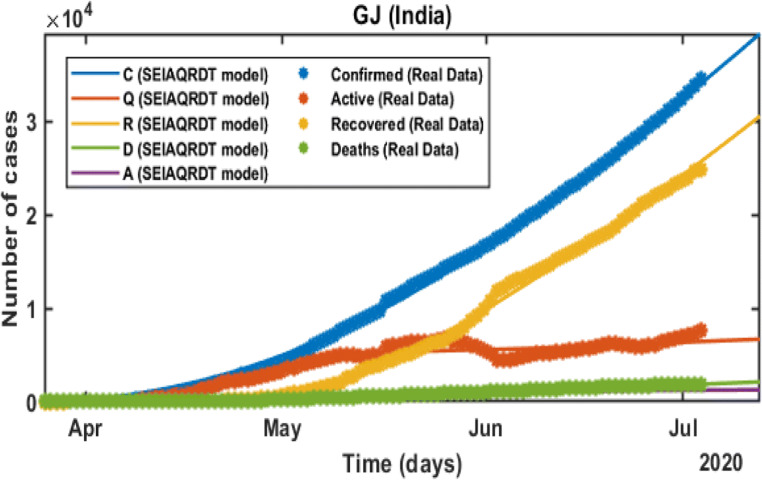
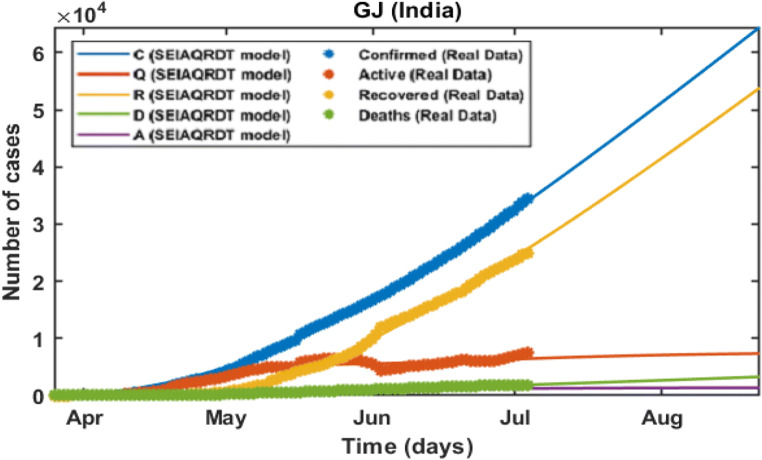
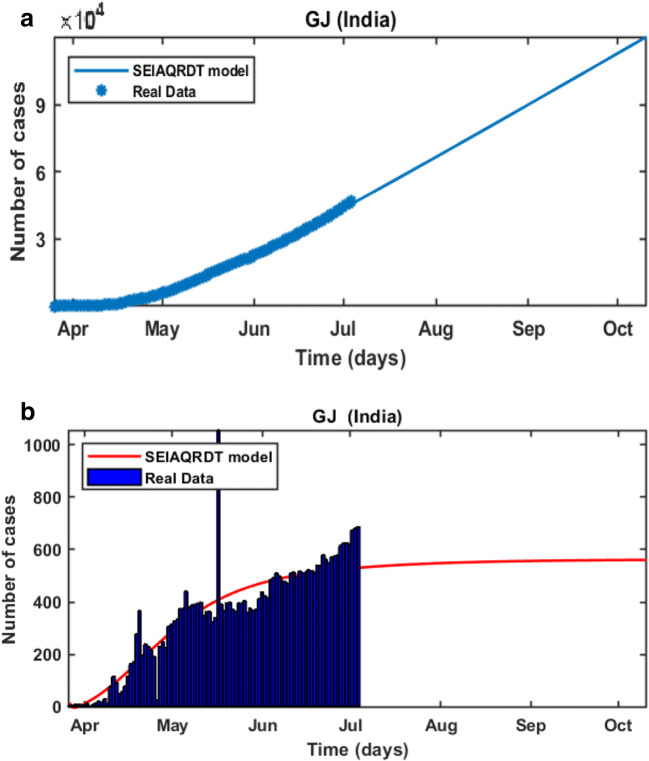
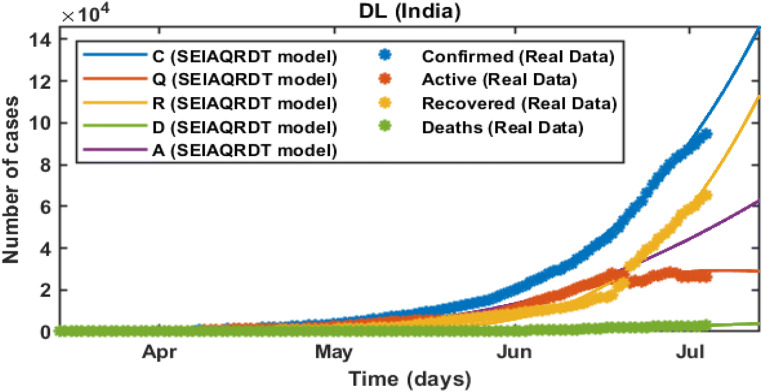
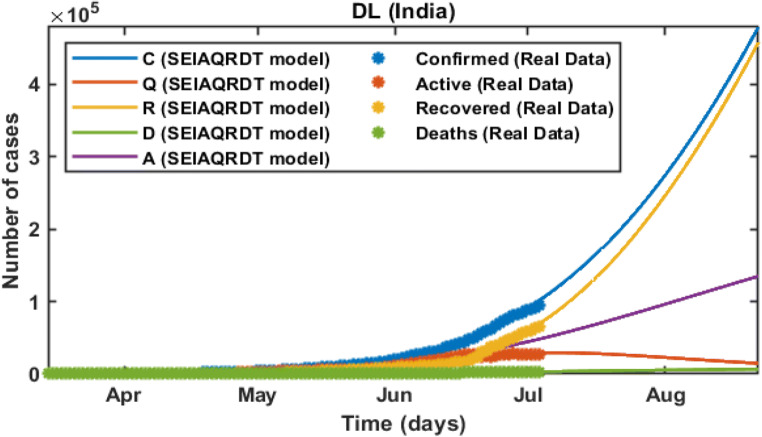
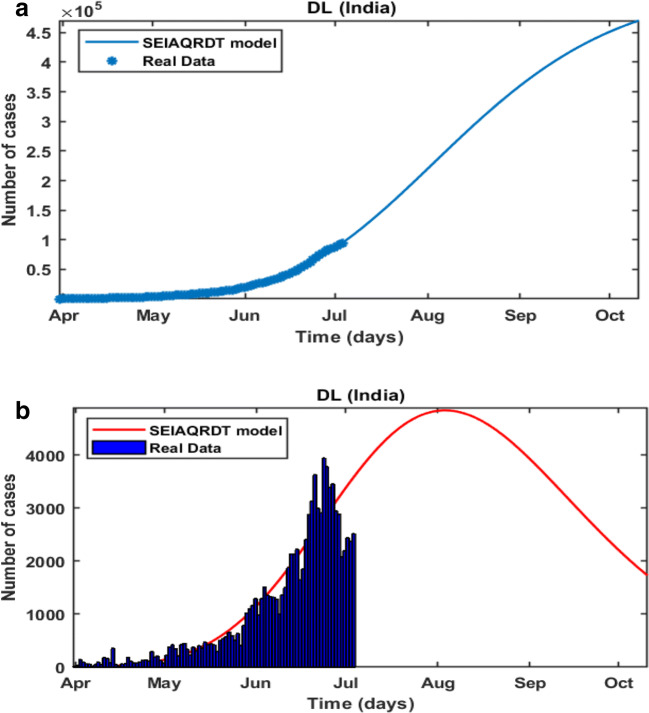
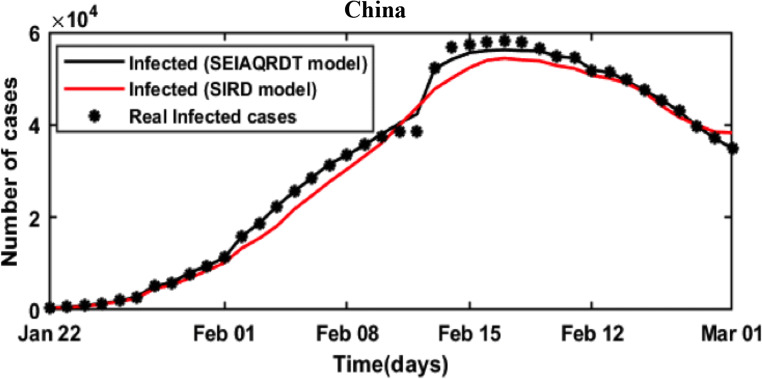
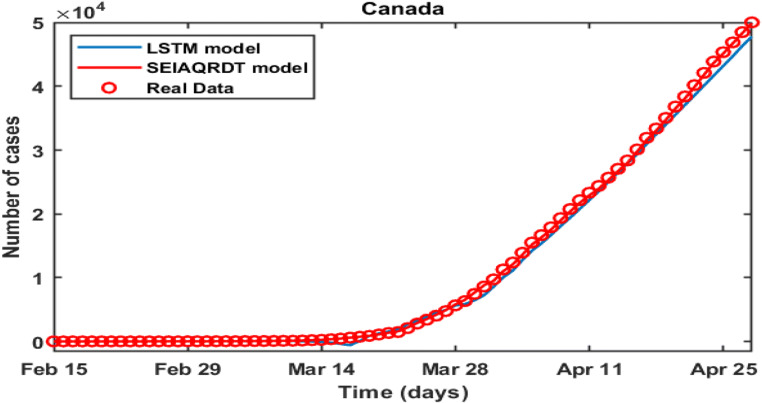
COVID-19 is a global pandemic declared by WHO. This pandemic requires the execution of planned control strategies, incorporating quarantine, self-isolation, and tracing of asymptomatic cases. Mathematical modeling is one of the prominent techniques for predicting and controlling the spread of COVID-19. The predictions of earlier proposed epidemiological models (e.g. SIR, SEIR, SIRD, SEIRD, etc.) are not much accurate due to lack of consideration for transmission of the epidemic during the latent period. Moreover, it is important to classify infected individuals to control this pandemic. Therefore, a new mathematical model is proposed to incorporate infected individuals based on whether they have symptoms or not. This model forecasts the number of cases more accurately, which may help in better planning of control strategies. The model consists of eight compartments: susceptible (S), exposed (E), infected (I), asymptomatic (A), quarantined (Q), recovered (R), deaths (D), and insusceptible (T), accumulatively named as SEIAQRDT. This model is employed to predict the pandemic results for India and its majorly affected states. The estimated number of cases using the SEIAQRDT model is compared with SIRD, SEIR, and LSTM models. The relative error square analysis is used to verify the accuracy of the proposed model. The simulation is done on real datasets and results show the effectiveness of the proposed approach. These results may help the government and individuals to make the planning in this pandemic situation.
COVID-19是世界卫生组织宣布的全球大流行病。这场大流行病需要实施有计划的控制策略,包括检疫、自我隔离以及追踪无症状病例。数学建模是预测和控制COVID-19传播的突出技术之一。由于早期提出的流行病学模型(如SIR、SEIR、SIRD、SEIRD等)没有考虑潜伏期内疫情的传播,其预测不太准确。此外,对感染个体进行分类对于控制这场大流行病很重要。因此,提出了一种新的数学模型,根据感染个体是否有症状来纳入其中。该模型能更准确地预测病例数量,这可能有助于更好地规划控制策略。该模型由八个部分组成:易感者(S)、暴露者(E)、感染者(I)、无症状者(A)、被隔离者(Q)、康复者(R)、死亡者(D)和免疫者(T),统称为SEIAQRDT。该模型用于预测印度及其主要受影响邦的大流行结果。将使用SEIAQRDT模型估计的病例数与SIRD、SEIR和LSTM模型进行比较。采用相对误差平方分析来验证所提模型的准确性。在真实数据集上进行了模拟,结果表明了所提方法的有效性。这些结果可能有助于政府和个人在这种大流行情况下进行规划。