Foran David J, Durbin Eric B, Chen Wenjin, Sadimin Evita, Sharma Ashish, Banerjee Imon, Kurc Tahsin, Li Nan, Stroup Antoinette M, Harris Gerald, Gu Annie, Schymura Maria, Gupta Rajarsi, Bremer Erich, Balsamo Joseph, DiPrima Tammy, Wang Feiqiao, Abousamra Shahira, Samaras Dimitris, Hands Isaac, Ward Kevin, Saltz Joel H
Center for Biomedical Informatics, Rutgers Cancer Institute of New Jersey, New Brunswick, NJ, USA.
Department of Pathology and Laboratory Medicine, Rutgers-Robert Wood Johnson Medical School, Piscataway, NJ, USA.
J Pathol Inform. 2022 Jan 5;13:5. doi: 10.4103/jpi.jpi_31_21. eCollection 2022.
Population-based state cancer registries are an authoritative source for cancer statistics in the United States. They routinely collect a variety of data, including patient demographics, primary tumor site, stage at diagnosis, first course of treatment, and survival, on every cancer case that is reported across all U.S. states and territories. The goal of our project is to enrich NCI's Surveillance, Epidemiology, and End Results (SEER) registry data with high-quality population-based biospecimen data in the form of digital pathology, machine-learning-based classifications, and quantitative histopathology imaging feature sets (referred to here as ).
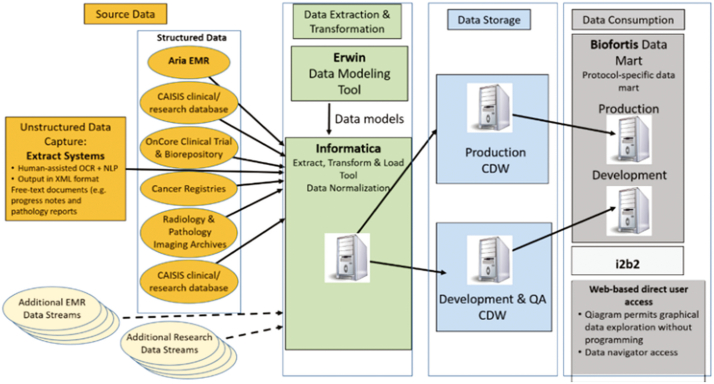
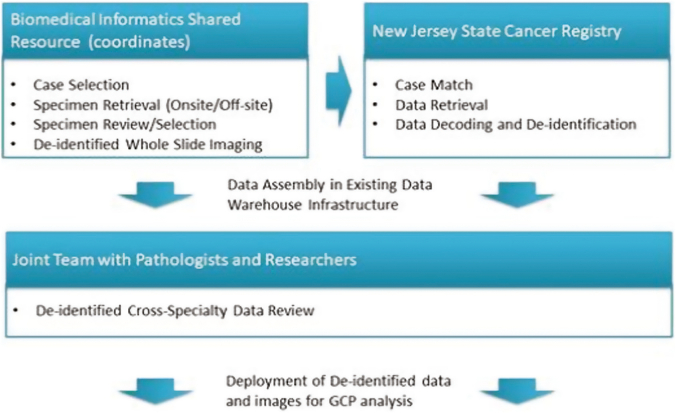
As part of the project, the underlying informatics infrastructure was designed, tested, and implemented through close collaboration with several participating SEER registries to ensure consistency with registry processes, computational scalability, and ability to support creation of population cohorts that span multiple sites. Utilizing computational imaging algorithms and methods to both generate indices and search for matches makes it possible to reduce inter- and intra-observer inconsistencies and to improve the objectivity with which large image repositories are interrogated.
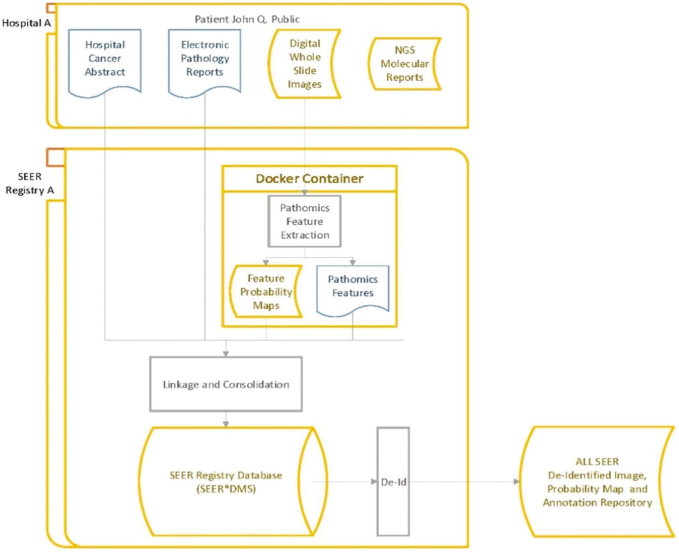
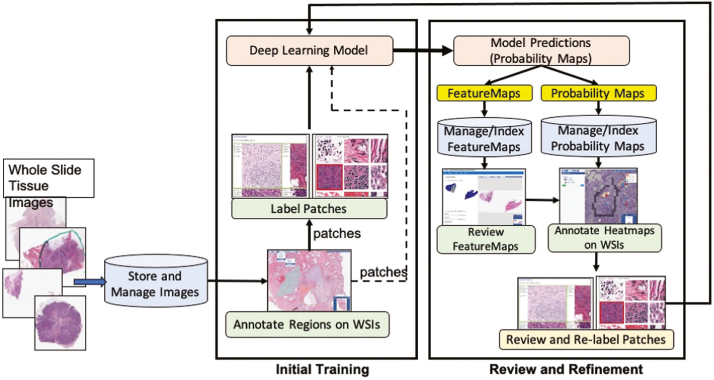
Our team has created and continues to expand a well-curated repository of high-quality digitized pathology images corresponding to subjects whose data are routinely collected by the collaborating registries. Our team has systematically deployed and tested key, visual analytic methods to facilitate automated creation of population cohorts for epidemiological studies and tools to support visualization of feature clusters and evaluation of whole-slide images. As part of these efforts, we are developing and optimizing advanced search and matching algorithms to facilitate automated, content-based retrieval of digitized specimens based on their underlying image features and staining characteristics.
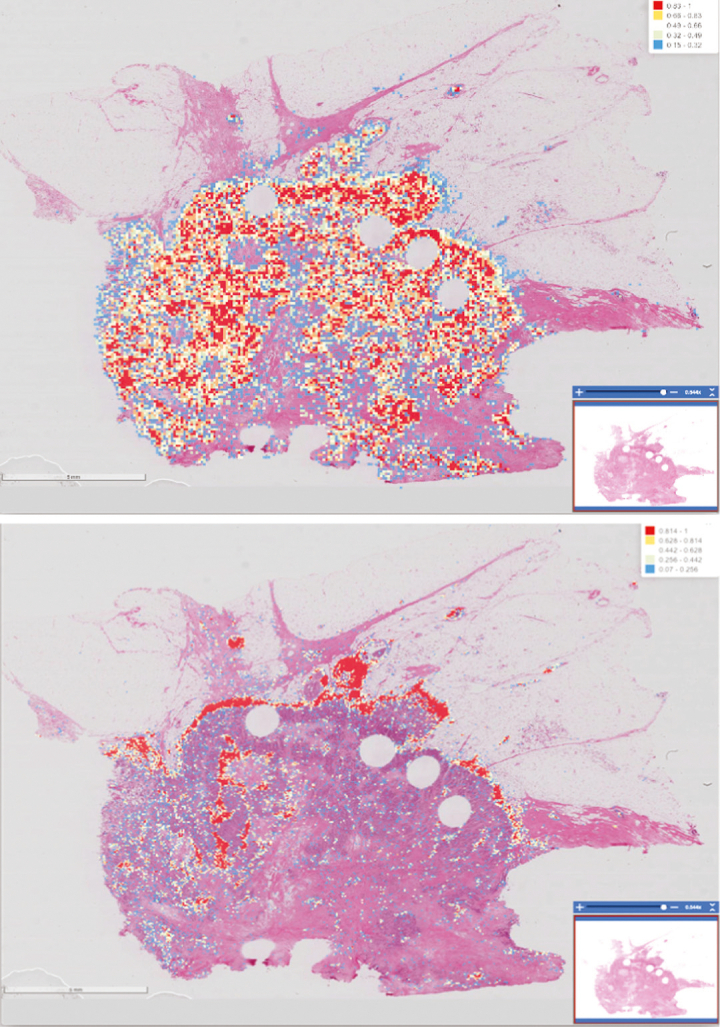
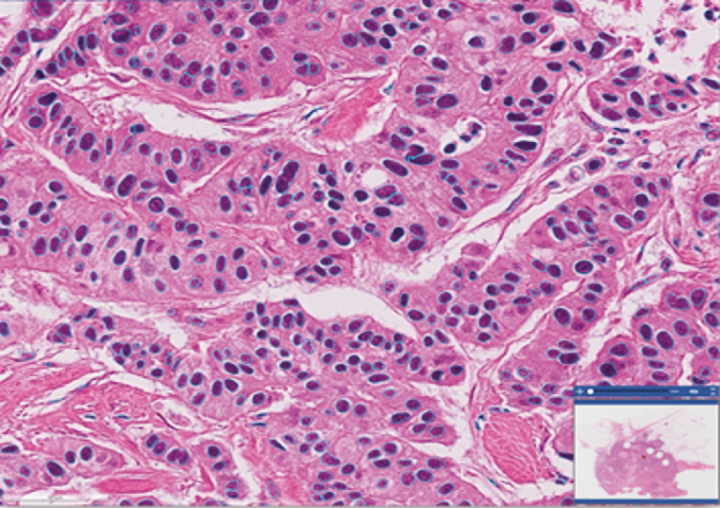
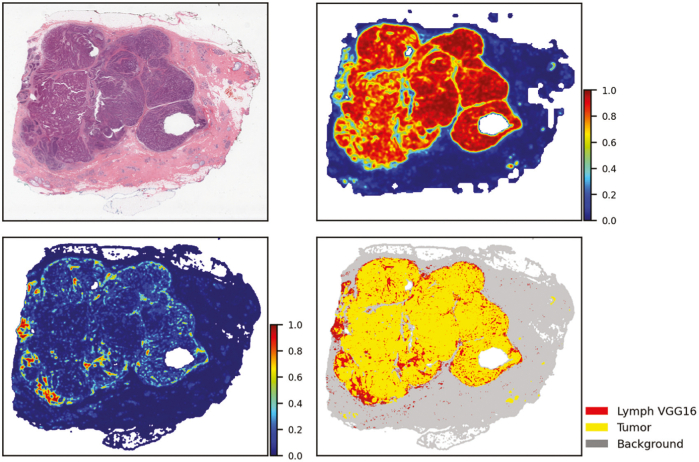
To meet the challenges of this project, we established the analytic pipelines, methods, and workflows to support the expansion and management of a growing repository of high-quality digitized pathology and information-rich, population cohorts containing objective imaging and clinical attributes to facilitate studies that seek to discriminate among different subtypes of disease, stratify patient populations, and perform comparisons of tumor characteristics within and across patient cohorts. We have also successfully developed a suite of tools based on a deep-learning method to perform quantitative characterizations of tumor regions, assess infiltrating lymphocyte distributions, and generate objective nuclear feature measurements. As part of these efforts, our team has implemented reliable methods that enable investigators to systematically search through large repositories to automatically retrieve digitized pathology specimens and correlated clinical data based on their computational signatures.
基于人群的州癌症登记处是美国癌症统计数据的权威来源。它们定期收集各类数据,包括患者人口统计学信息、原发肿瘤部位、诊断时的分期、初始治疗方案以及生存情况等,涉及美国所有州和领地上报的每一例癌症病例。我们项目的目标是以数字病理学、基于机器学习的分类以及定量组织病理学成像特征集(此处称为[未提及具体名称])的形式,用高质量的基于人群的生物样本数据丰富美国国立癌症研究所(NCI)的监测、流行病学和最终结果(SEER)登记处数据。
作为项目的一部分,通过与多个参与的SEER登记处密切合作,设计、测试并实施了基础信息学基础设施,以确保与登记处流程一致、具备计算可扩展性以及支持创建跨多个地点的人群队列的能力。利用计算成像算法和方法来生成索引并寻找匹配项,能够减少观察者之间和观察者内部的不一致性,并提高查询大型图像存储库的客观性。
我们的团队已经创建并持续扩充一个精心整理的高质量数字化病理图像存储库,这些图像对应的数据由合作登记处常规收集。我们的团队系统地部署并测试了关键的视觉分析方法,以促进为流行病学研究自动创建人群队列,以及支持特征聚类可视化和全切片图像评估的工具。作为这些努力的一部分,我们正在开发和优化先进的搜索和匹配算法,以便基于数字化标本的基础图像特征和染色特性,促进基于内容的自动检索。
为应对该项目的挑战,我们建立了分析管道、方法和工作流程,以支持扩充和管理不断增长的高质量数字化病理学存储库以及包含客观成像和临床属性的信息丰富的人群队列,从而便于开展旨在区分疾病不同亚型、对患者群体进行分层以及在患者队列内部和之间比较肿瘤特征的研究。我们还成功开发了一套基于深度学习方法的工具,用于对肿瘤区域进行定量表征、评估浸润淋巴细胞分布并生成客观的核特征测量值。作为这些努力的一部分,我们的团队实施了可靠的方法,使研究人员能够系统地搜索大型存储库,以根据其计算特征自动检索数字化病理标本和相关临床数据。