Huyut M T
Department of Biostatistics and Medical Informatics, Medical Faculty, Erzincan Binali Yıldırım University, 24100, Erzincan, Turkey.
Ing Rech Biomed. 2023 Feb;44(1):100725. doi: 10.1016/j.irbm.2022.05.006. Epub 2022 Jun 1.
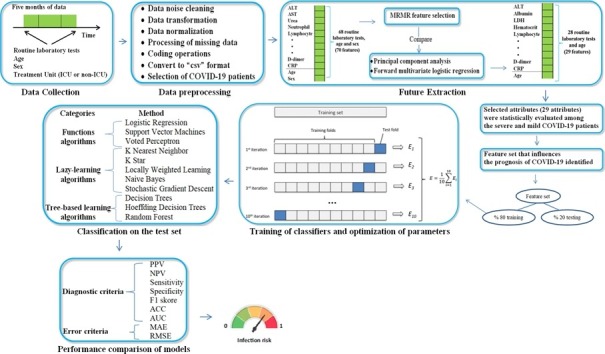
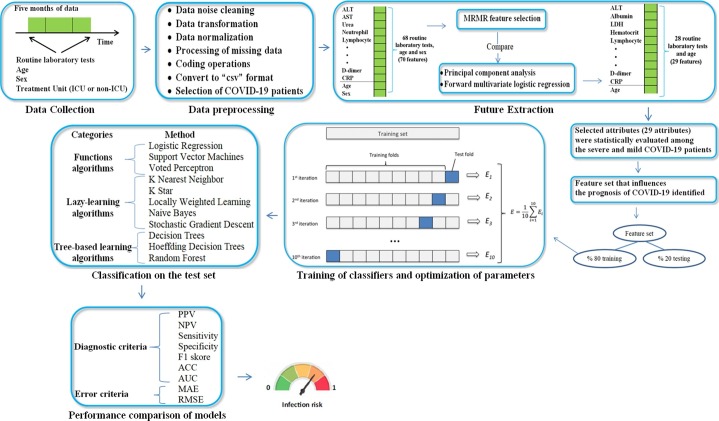
When the prognosis of COVID-19 disease can be detected early, the intense-pressure and loss of workforce in health-services can be partially reduced. The primary-purpose of this article is to determine the feature-dataset consisting of the routine-blood-values (RBV) and demographic-data that affect the prognosis of COVID-19. Second, by applying the feature-dataset to the supervised machine-learning (ML) models, it is to identify severely and mildly infected COVID-19 patients at the time of admission.
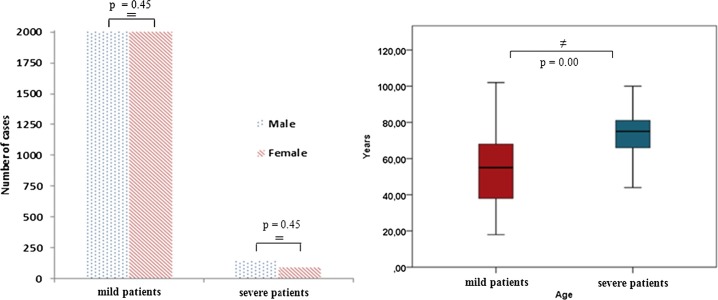
The sample of this study consists of severely (n = 192) and mildly (n = 4010) infected-patients hospitalized with the diagnosis of COVID-19 between March-September, 2021. The RBV-data measured at the time of admission and age-gender characteristics of these patients were analyzed retrospectively. For the selection of the features, the minimum-redundancy-maximum-relevance (MRMR) method, principal-components-analysis and forward-multiple-logistics-regression analyzes were used. The features set were statistically compared between mild and severe infected-patients. Then, the performances of various supervised-ML-models were compared in identifying severely and mildly infected-patients using the feature set.
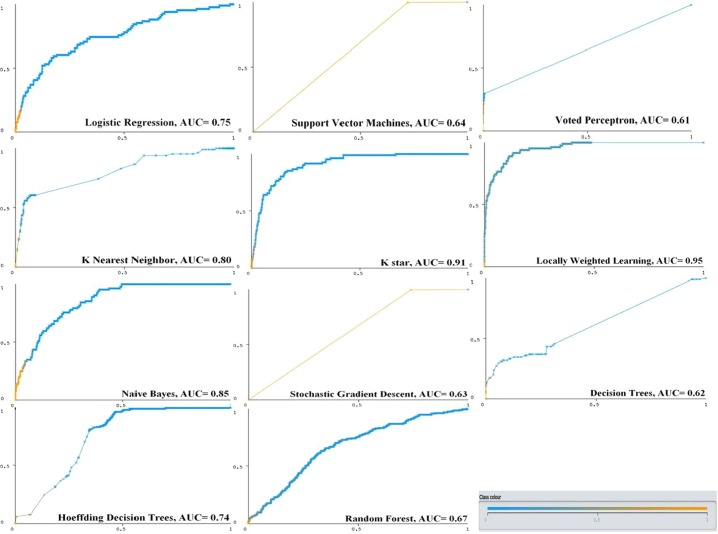
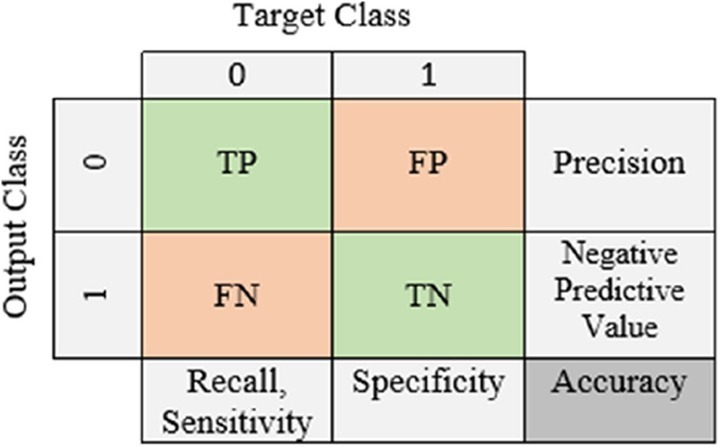
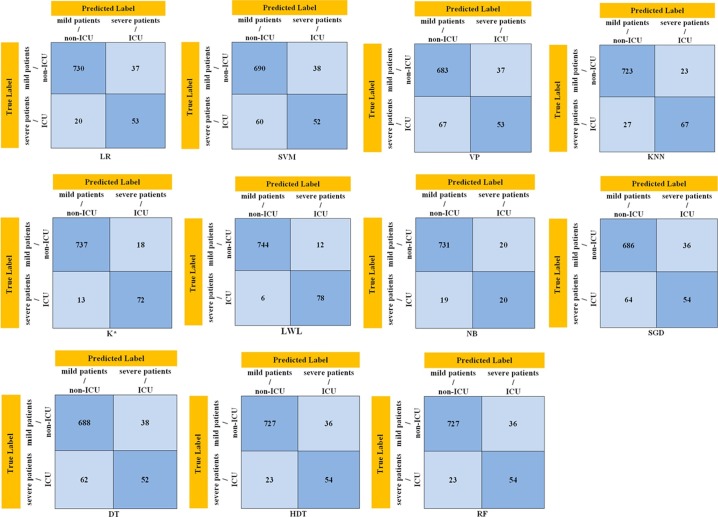
In this study, 28 RBV-parameters and age-variable were found as the feature-dataset. The effect of features on the prognosis of the disease has been clinically proven. The ML-models with the highest overall-accuracy in identifying patient-groups were found respectively, as follows: local-weighted-learning (LWL)-97.86%, K-star (K*)-96.31%, Naive-Bayes (NB)-95.36% and k-nearest-neighbor (KNN)-94.05%. Also, the most successful models with the highest area-under-the-receiver-operating-characteristic-curve (AUC) values in identifying patient groups were found respectively, as follows: LWL-0.95%, K*-0.91%, NB-0.85% and KNN-0.75%.
The findings in this article have significant a motivation for the healthcare professionals to detect at admission severely and mildly infected COVID-19 patients.
当能够早期检测出新冠肺炎疾病的预后时,卫生服务中高强度的压力和劳动力流失情况可得到部分缓解。本文的主要目的是确定由常规血液值(RBV)和影响新冠肺炎预后的人口统计学数据组成的特征数据集。其次,通过将该特征数据集应用于监督式机器学习(ML)模型,在入院时识别出新冠肺炎重症和轻症患者。
本研究样本包括2021年3月至9月期间因新冠肺炎诊断住院的重症(n = 192)和轻症(n = 4010)感染患者。回顾性分析了这些患者入院时测量的RBV数据以及年龄和性别特征。为了选择特征,使用了最小冗余最大相关性(MRMR)方法、主成分分析和向前多元逻辑回归分析。对轻症和重症感染患者的特征集进行了统计学比较。然后,使用该特征集比较了各种监督式ML模型在识别重症和轻症感染患者方面的性能。
在本研究中,发现28个RBV参数和年龄变量为特征数据集。这些特征对疾病预后的影响已得到临床证实。在识别患者组方面总体准确率最高的ML模型分别如下:局部加权学习(LWL)- 97.86%,K星(K*)- 96.31%,朴素贝叶斯(NB)- 95.36%和k近邻(KNN)- 94.05%。此外,在识别患者组方面具有最高受试者工作特征曲线下面积(AUC)值的最成功模型分别如下:LWL - 0.95%,K* - 0.91%,NB - 0.85%和KNN - 0.75%。
本文的研究结果对医护人员在入院时识别新冠肺炎重症和轻症患者具有重要的推动作用。