Soroski Thomas, da Cunha Vasco Thiago, Newton-Mason Sally, Granby Saffrin, Lewis Caitlin, Harisinghani Anuj, Rizzo Matteo, Conati Cristina, Murray Gabriel, Carenini Giuseppe, Field Thalia S, Jang Hyeju
Vancouver Stroke Program and Division of Neurology, Faculty of Medicine, University of British Columbia, Vancouver, BC, Canada.
Department of Computer Science, Faculty of Science, University of British Columbia, Vancouver, BC, Canada.
JMIR Aging. 2022 Sep 21;5(3):e33460. doi: 10.2196/33460.
Speech data for medical research can be collected noninvasively and in large volumes. Speech analysis has shown promise in diagnosing neurodegenerative disease. To effectively leverage speech data, transcription is important, as there is valuable information contained in lexical content. Manual transcription, while highly accurate, limits the potential scalability and cost savings associated with language-based screening.
To better understand the use of automatic transcription for classification of neurodegenerative disease, namely, Alzheimer disease (AD), mild cognitive impairment (MCI), or subjective memory complaints (SMC) versus healthy controls, we compared automatically generated transcripts against transcripts that went through manual correction.
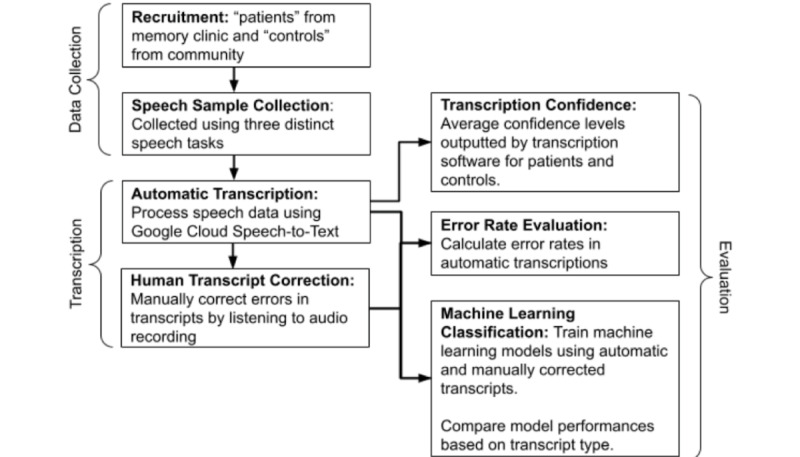
We recruited individuals from a memory clinic ("patients") with a diagnosis of mild-to-moderate AD, (n=44, 30%), MCI (n=20, 13%), SMC (n=8, 5%), as well as healthy controls (n=77, 52%) living in the community. Participants were asked to describe a standardized picture, read a paragraph, and recall a pleasant life experience. We compared transcripts generated using Google speech-to-text software to manually verified transcripts by examining transcription confidence scores, transcription error rates, and machine learning classification accuracy. For the classification tasks, logistic regression, Gaussian naive Bayes, and random forests were used.
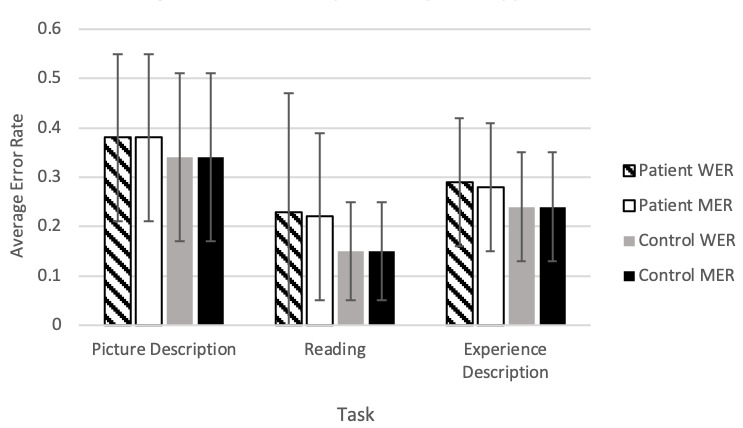
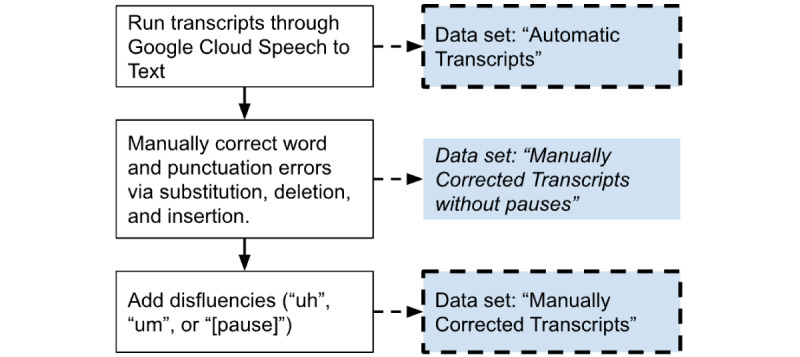
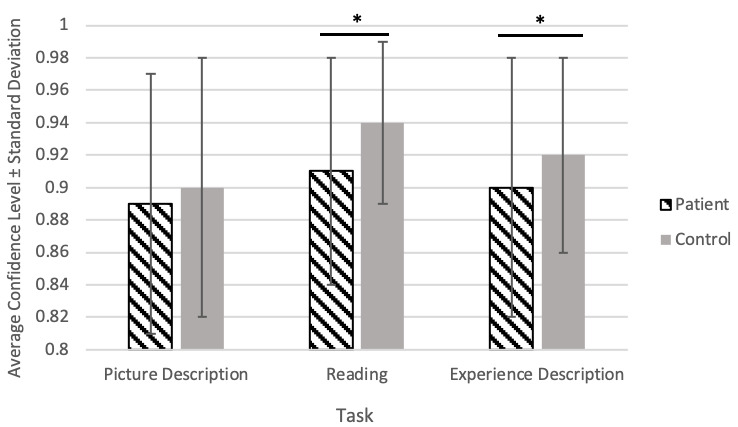
The transcription software showed higher confidence scores (P<.001) and lower error rates (P>.05) for speech from healthy controls compared with patients. Classification models using human-verified transcripts significantly (P<.001) outperformed automatically generated transcript models for both spontaneous speech tasks. This comparison showed no difference in the reading task. Manually adding pauses to transcripts had no impact on classification performance. However, manually correcting both spontaneous speech tasks led to significantly higher performances in the machine learning models.
We found that automatically transcribed speech data could be used to distinguish patients with a diagnosis of AD, MCI, or SMC from controls. We recommend a human verification step to improve the performance of automatic transcripts, especially for spontaneous tasks. Moreover, human verification can focus on correcting errors and adding punctuation to transcripts. However, manual addition of pauses is not needed, which can simplify the human verification step to more efficiently process large volumes of speech data.
医学研究的语音数据可以通过非侵入性方式大量收集。语音分析在神经退行性疾病的诊断中显示出前景。为了有效利用语音数据,转录很重要,因为词汇内容中包含有价值的信息。手动转录虽然非常准确,但限制了与基于语言的筛查相关的潜在可扩展性和成本节约。
为了更好地理解自动转录在神经退行性疾病分类中的应用,即阿尔茨海默病(AD)、轻度认知障碍(MCI)或主观记忆障碍(SMC)与健康对照的分类,我们将自动生成的转录本与经过人工校正的转录本进行了比较。
我们从一家记忆诊所招募了个体(“患者”),其中包括诊断为轻度至中度AD的患者(n = 44,30%)、MCI患者(n = 20,13%)、SMC患者(n = 8,5%),以及社区中的健康对照(n = 77,52%)。参与者被要求描述一幅标准化图片、阅读一段文字并回忆一次愉快的生活经历。我们通过检查转录置信度分数、转录错误率和机器学习分类准确率,将使用谷歌语音转文本软件生成的转录本与人工验证的转录本进行了比较。对于分类任务,使用了逻辑回归、高斯朴素贝叶斯和随机森林。
与患者相比,转录软件对健康对照的语音显示出更高的置信度分数(P <.001)和更低的错误率(P >.05)。对于两项自发语音任务,使用人工验证转录本的分类模型显著(P <.001)优于自动生成转录本的模型。这种比较在阅读任务中没有差异。人工在转录本中添加停顿对分类性能没有影响。然而,对两项自发语音任务进行人工校正会使机器学习模型的性能显著提高。
我们发现自动转录的语音数据可用于区分诊断为AD、MCI或SMC的患者与对照。我们建议进行人工验证步骤以提高自动转录本的性能,特别是对于自发任务。此外,人工验证可以专注于纠正错误和在转录本中添加标点。然而,不需要人工添加停顿,这可以简化人工验证步骤以更高效地处理大量语音数据。