Department of Computer Software Engineering, National University of Sciences and Technology, Islamabad 44000, Pakistan.
Department of Computer Science, Shaheed Zulfikar Ali Bhutto Institute of Science and Technology, Islamabad 44000, Pakistan.
Sensors (Basel). 2022 Dec 13;22(24):9775. doi: 10.3390/s22249775.
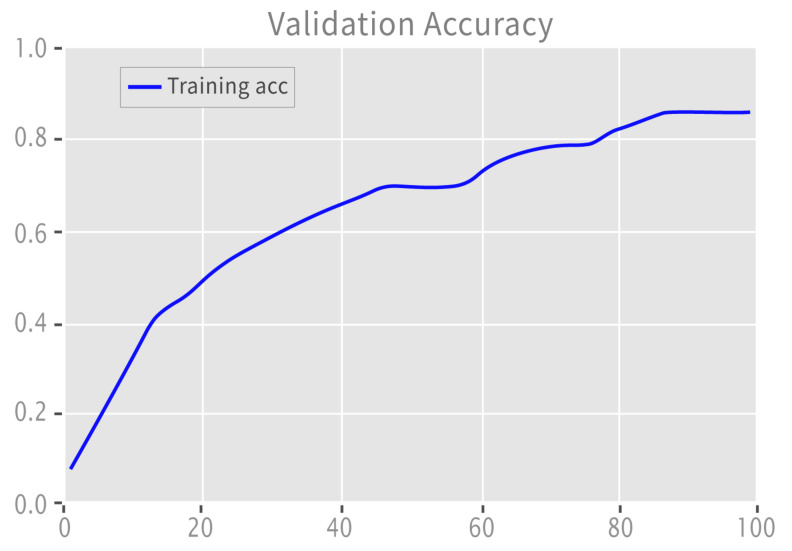
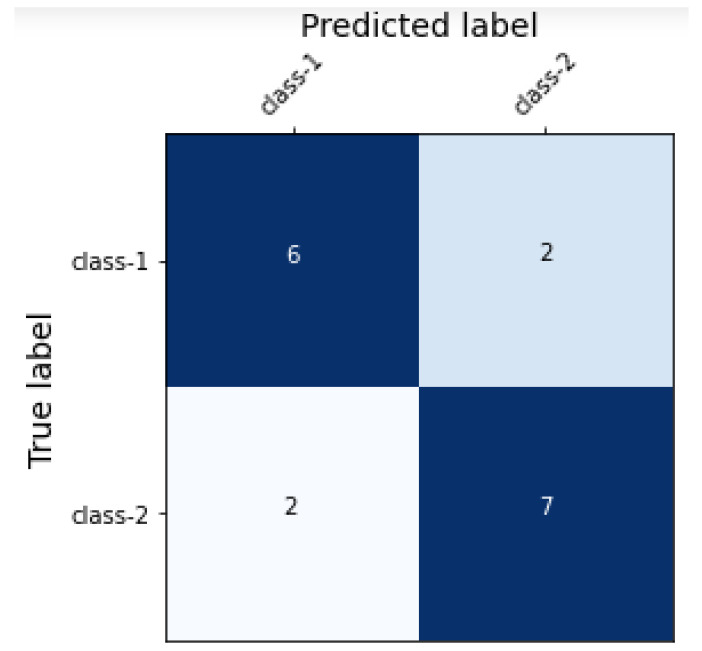
In today's world, mental health diseases have become highly prevalent, and depression is one of the mental health problems that has become widespread. According to WHO reports, depression is the second-leading cause of the global burden of diseases. In the proliferation of such issues, social media has proven to be a great platform for people to express themselves. Thus, a user's social media can speak a great deal about his/her emotional state and mental health. Considering the high pervasiveness of the disease, this paper presents a novel framework for depression detection from textual data, employing Natural Language Processing and deep learning techniques. For this purpose, a dataset consisting of tweets was created, which were then manually annotated by the domain experts to capture the implicit and explicit depression context. Two variations of the dataset were created, on having binary and one ternary labels, respectively. Ultimately, a deep-learning-based hybrid Sequence, Semantic, Context Learning (SSCL) classification framework with a self-attention mechanism is proposed that utilizes GloVe (pre-trained word embeddings) for feature extraction; LSTM and CNN were used to capture the sequence and semantics of tweets; finally, the GRUs and self-attention mechanism were used, which focus on contextual and implicit information in the tweets. The framework outperformed the existing techniques in detecting the explicit and implicit context, with an accuracy of 97.4 for binary labeled data and 82.9 for ternary labeled data. We further tested our proposed SSCL framework on unseen data (random tweets), for which an F1-score of 94.4 was achieved. Furthermore, in order to showcase the strengths of the proposed framework, we validated it on the "News Headline Data set" for sarcasm detection, considering a dataset from a different domain. It also outmatched the performance of existing techniques in cross-domain validation.
在当今世界,精神疾病已高度流行,抑郁症是一种广泛存在的心理健康问题。根据世界卫生组织的报告,抑郁症是全球第二大疾病负担原因。在这些问题的泛滥中,社交媒体已被证明是人们表达自我的绝佳平台。因此,用户的社交媒体可以很好地反映其情绪状态和心理健康。鉴于该疾病的高度普遍性,本文提出了一种从文本数据中检测抑郁症的新框架,采用自然语言处理和深度学习技术。为此,创建了一个包含推文的数据集,然后由领域专家手动对其进行注释,以捕捉隐含和显式的抑郁语境。创建了两个变体数据集,分别具有二进制和三分类标签。最终,提出了一种基于深度学习的混合序列、语义、上下文学习(SSCL)分类框架,具有自注意力机制,该框架利用 GloVe(预训练单词嵌入)进行特征提取;使用 LSTM 和 CNN 捕获推文的序列和语义;最后,使用 GRUs 和自注意力机制,重点关注推文的上下文和隐含信息。该框架在检测显式和隐含语境方面优于现有技术,对于二进制标记数据的准确率为 97.4%,对于三分类标记数据的准确率为 82.9%。我们进一步在未见数据(随机推文)上测试了我们提出的 SSCL 框架,其 F1 得分为 94.4。此外,为了展示所提出框架的优势,我们在“新闻标题数据集”上验证了其在不同领域的讽刺检测,其性能优于现有技术在跨领域验证中的性能。