Eawag, Swiss Federal Institute of Aquatic Science and Technology, Dübendorf, Switzerland.
Swiss Data Science Center (SDSC), Zürich, Switzerland.
Sci Data. 2023 Oct 18;10(1):718. doi: 10.1038/s41597-023-02612-2.
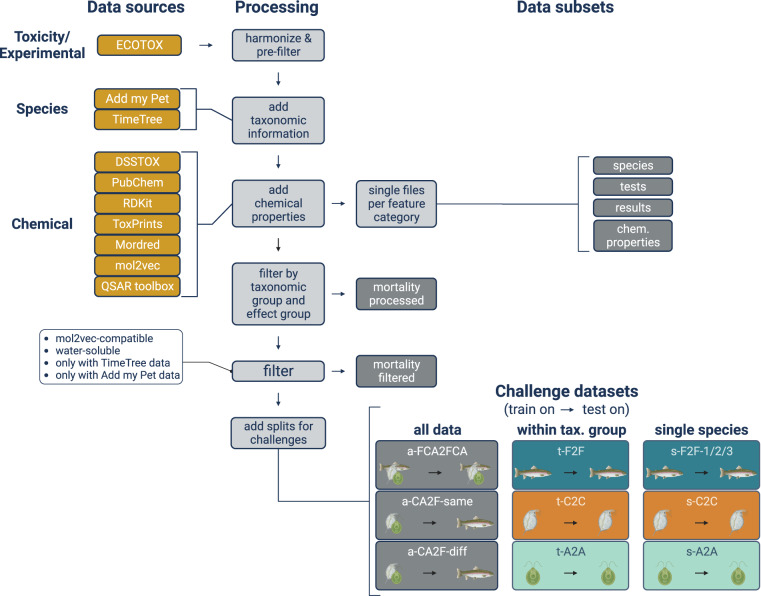
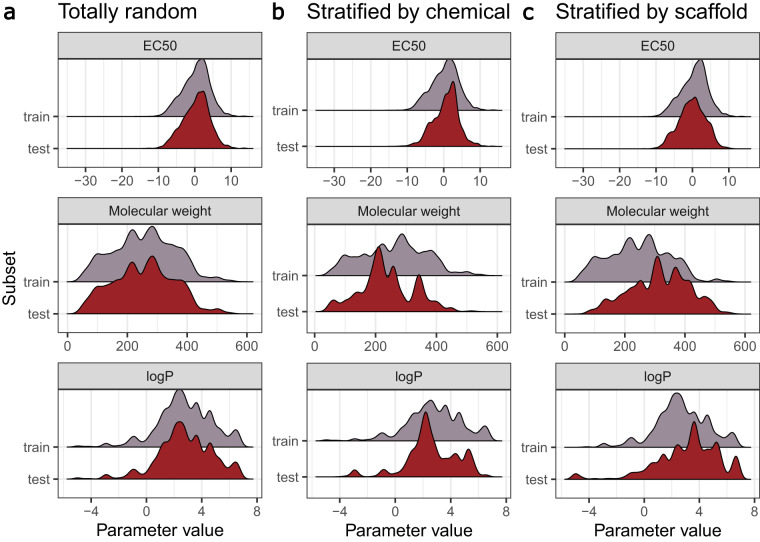
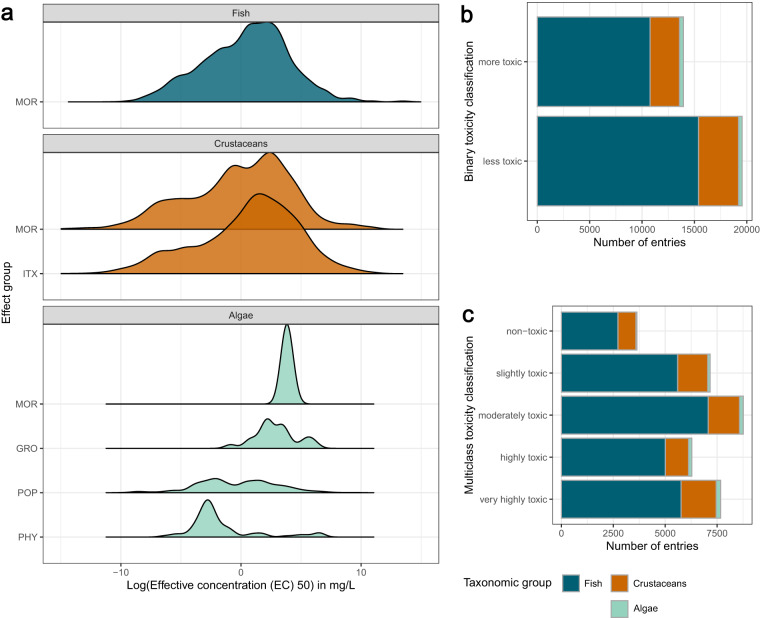
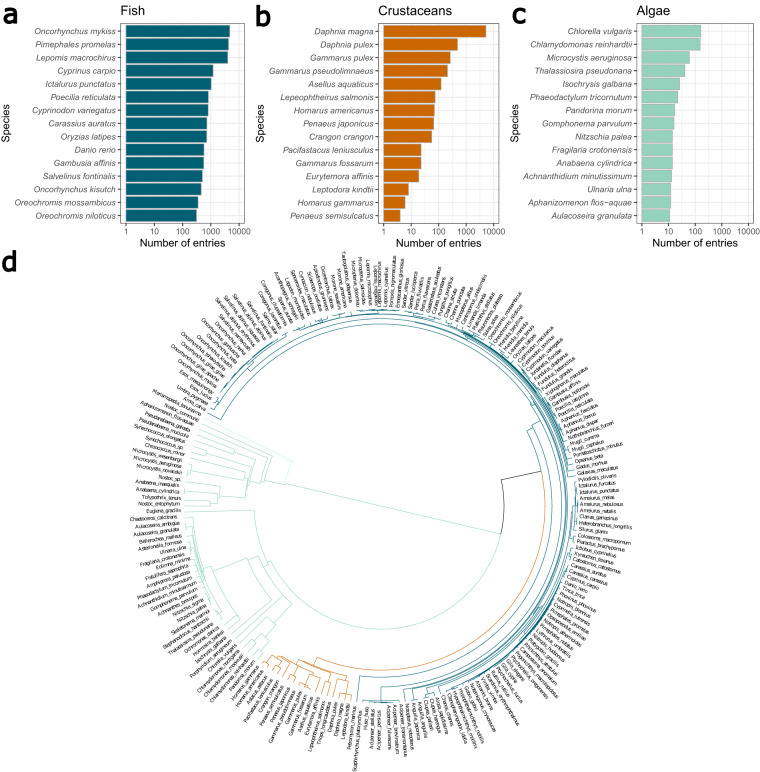
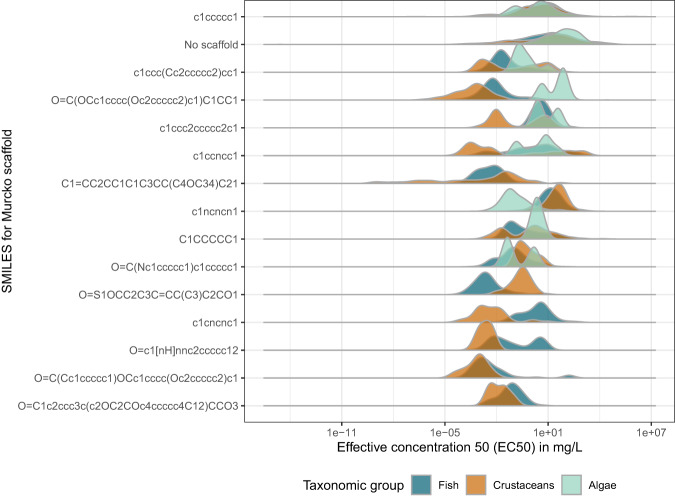
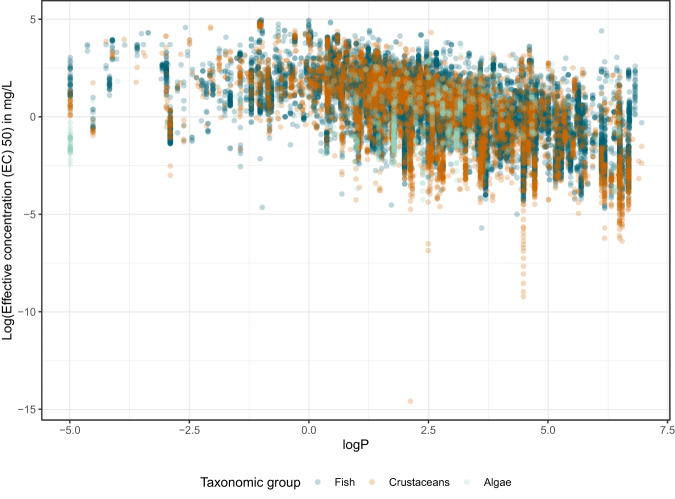
The use of machine learning for predicting ecotoxicological outcomes is promising, but underutilized. The curation of data with informative features requires both expertise in machine learning as well as a strong biological and ecotoxicological background, which we consider a barrier of entry for this kind of research. Additionally, model performances can only be compared across studies when the same dataset, cleaning, and splittings were used. Therefore, we provide ADORE, an extensive and well-described dataset on acute aquatic toxicity in three relevant taxonomic groups (fish, crustaceans, and algae). The core dataset describes ecotoxicological experiments and is expanded with phylogenetic and species-specific data on the species as well as chemical properties and molecular representations. Apart from challenging other researchers to try and achieve the best model performances across the whole dataset, we propose specific relevant challenges on subsets of the data and include datasets and splittings corresponding to each of these challenge as well as in-depth characterization and discussion of train-test splitting approaches.
机器学习在预测生态毒理学结果方面具有广阔的应用前景,但目前的应用还不够充分。具有信息特征的数据编目既需要机器学习方面的专业知识,也需要坚实的生物学和生态毒理学背景,我们认为这是此类研究的一个进入门槛。此外,只有当使用相同的数据集、清理和拆分时,才能对不同研究中的模型性能进行比较。因此,我们提供了 ADORE,这是一个关于三个相关分类群(鱼类、甲壳类动物和藻类)急性水生毒性的广泛且描述详尽的数据集。核心数据集描述了生态毒理学实验,并扩展了物种的系统发育和物种特异性数据以及化学性质和分子表示。除了挑战其他研究人员尝试在整个数据集中实现最佳模型性能之外,我们还在数据的子集上提出了具体的相关挑战,并包含了每个挑战对应的数据集和拆分,以及对训练-测试拆分方法进行深入的特征描述和讨论。