Zhao Chongyue, Xu Zhongli, Wang Xinjun, Tao Shiyue, MacDonald William A, He Kun, Poholek Amanda C, Chen Kong, Huang Heng, Chen Wei
Department of Pediatrics, University of Pittsburgh, Pittsburgh, 15224, Pennsylvania, USA.
School of Medicine, Tsinghua University, Beijing, 100084, Beijing, China.
Brief Bioinform. 2024 Jan 22;25(2). doi: 10.1093/bib/bbae052.
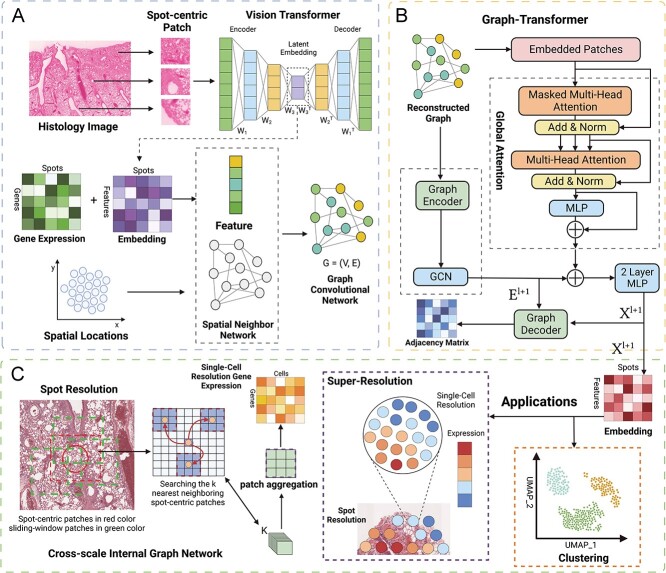
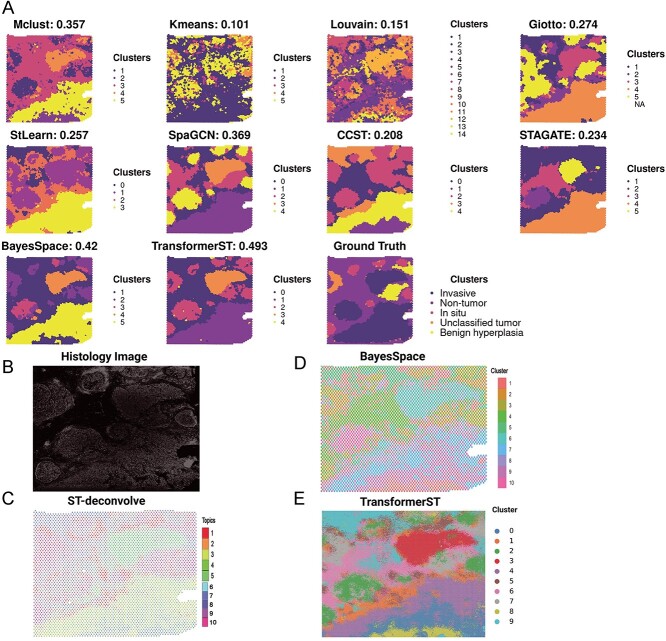
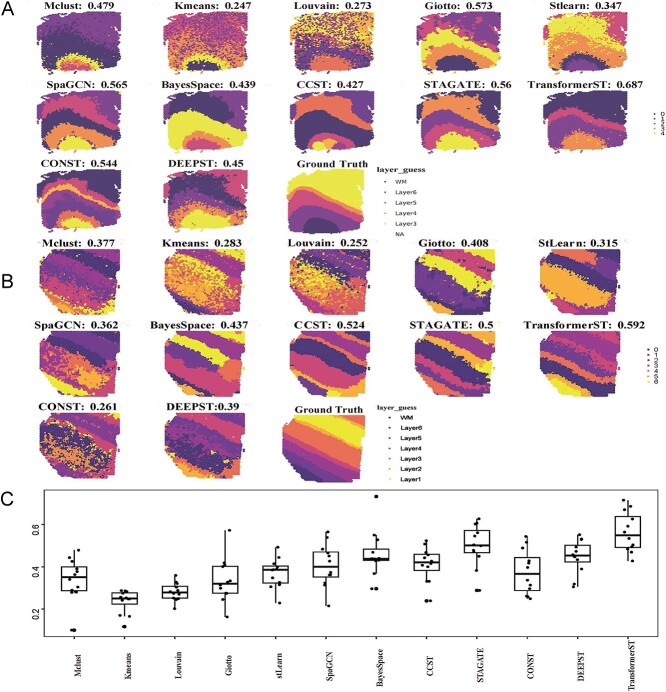
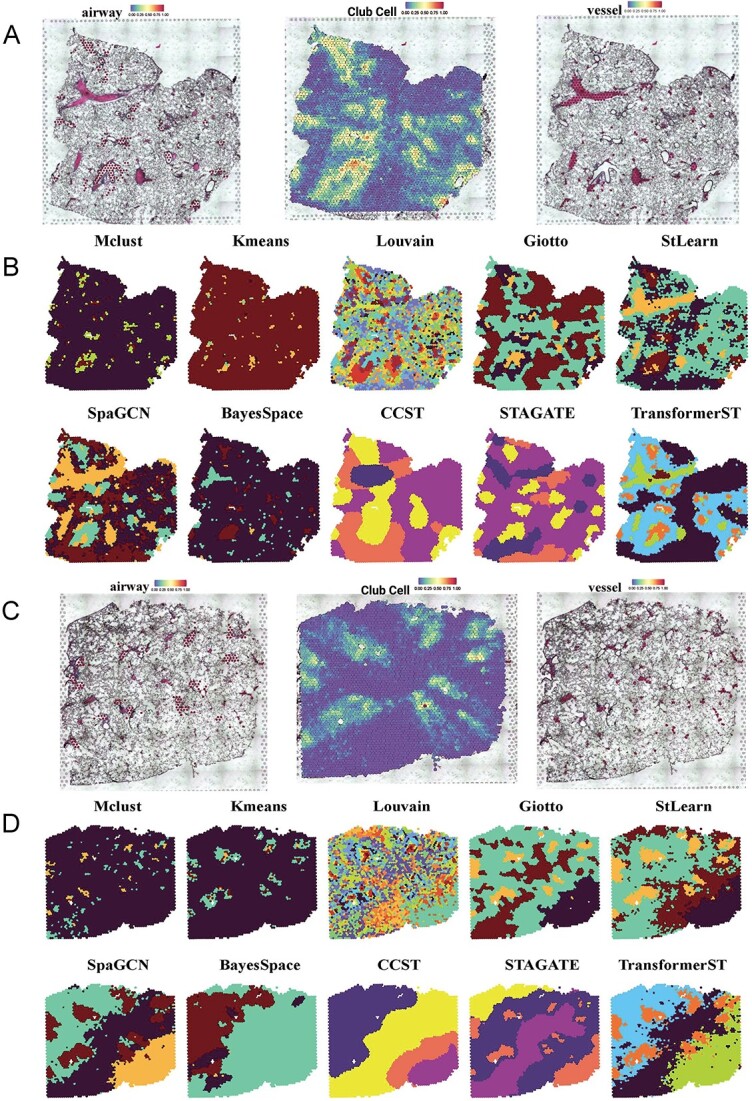
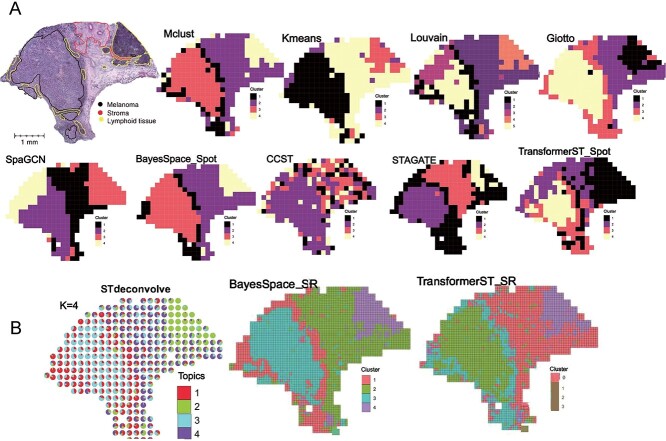
Spatial transcriptomics technologies have shed light on the complexities of tissue structures by accurately mapping spatial microenvironments. Nonetheless, a myriad of methods, especially those utilized in platforms like Visium, often relinquish spatial details owing to intrinsic resolution limitations. In response, we introduce TransformerST, an innovative, unsupervised model anchored in the Transformer architecture, which operates independently of references, thereby ensuring cost-efficiency by circumventing the need for single-cell RNA sequencing. TransformerST not only elevates Visium data from a multicellular level to a single-cell granularity but also showcases adaptability across diverse spatial transcriptomics platforms. By employing a vision transformer-based encoder, it discerns latent image-gene expression co-representations and is further enhanced by spatial correlations, derived from an adaptive graph Transformer module. The sophisticated cross-scale graph network, utilized in super-resolution, significantly boosts the model's accuracy, unveiling complex structure-functional relationships within histology images. Empirical evaluations validate its adeptness in revealing tissue subtleties at the single-cell scale. Crucially, TransformerST adeptly navigates through image-gene co-representation, maximizing the synergistic utility of gene expression and histology images, thereby emerging as a pioneering tool in spatial transcriptomics. It not only enhances resolution to a single-cell level but also introduces a novel approach that optimally utilizes histology images alongside gene expression, providing a refined lens for investigating spatial transcriptomics.
空间转录组学技术通过精确绘制空间微环境,揭示了组织结构的复杂性。尽管如此,众多方法,尤其是像Visium平台中使用的那些方法,由于其固有的分辨率限制,常常会丢失空间细节。作为回应,我们引入了TransformerST,这是一种基于Transformer架构的创新型无监督模型,它独立于参考数据运行,从而通过避免单细胞RNA测序的需求确保了成本效益。TransformerST不仅将Visium数据从多细胞水平提升到单细胞粒度,还展示了在不同空间转录组学平台上的适应性。通过采用基于视觉Transformer的编码器,它能够识别潜在的图像-基因表达共同表示,并通过自适应图Transformer模块导出的空间相关性得到进一步增强。用于超分辨率的复杂跨尺度图网络显著提高了模型的准确性,揭示了组织学图像中复杂的结构-功能关系。实证评估验证了其在单细胞尺度上揭示组织细微差别的能力。至关重要的是,TransformerST能够巧妙地在图像-基因共同表示中导航,最大限度地发挥基因表达和组织学图像的协同效用,从而成为空间转录组学中的开创性工具。它不仅将分辨率提高到单细胞水平,还引入了一种新颖的方法,即最佳地利用组织学图像和基因表达,为研究空间转录组学提供了一个精细的视角。