Zanger-Tishler Michael, Nyarko Julian, Goel Sharad
Sociology and Social Policy, Harvard University, Cambridge, MA 02138, USA.
Stanford Law School, Stanford, CA 94305, USA.
Sci Adv. 2024 Mar 29;10(13):eadi8411. doi: 10.1126/sciadv.adi8411.
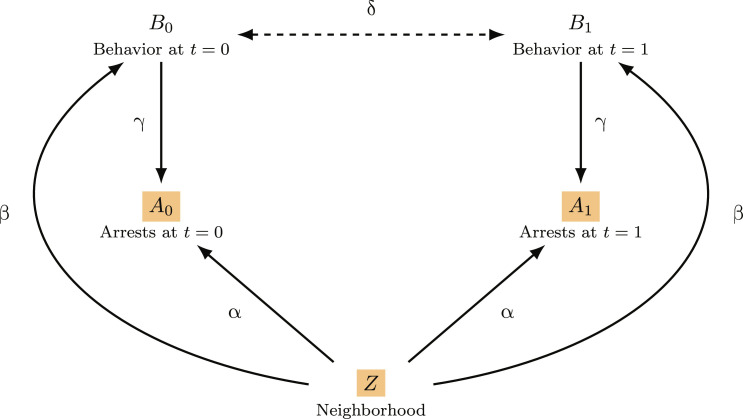
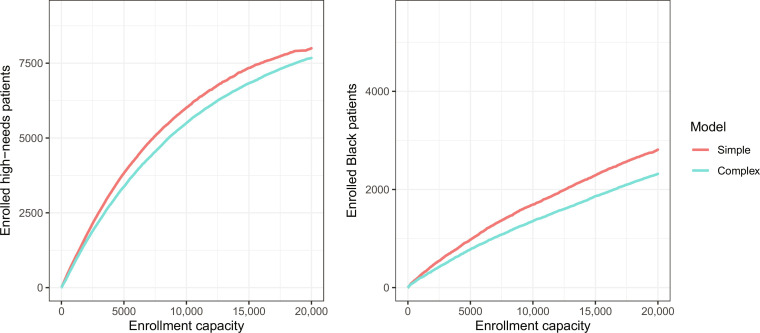
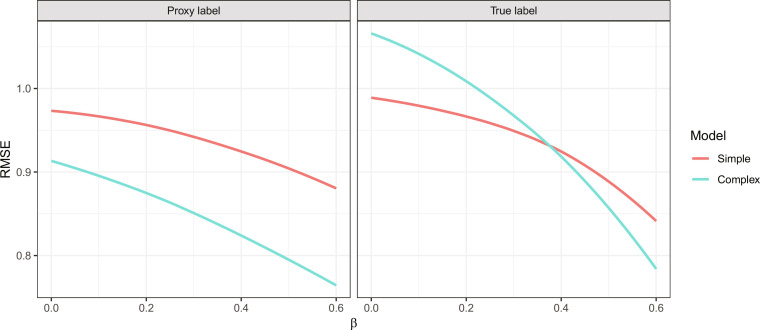
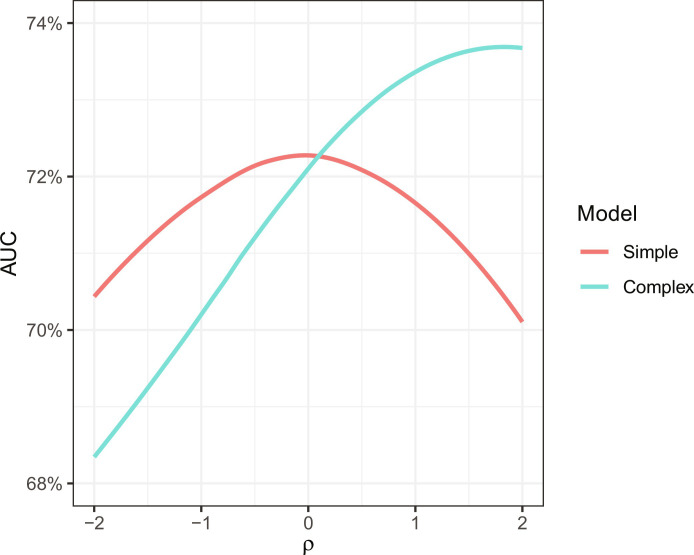
In designing risk assessment algorithms, many scholars promote a "kitchen sink" approach, reasoning that more information yields more accurate predictions. We show, however, that this rationale often fails when algorithms are trained to predict a proxy of the true outcome, for instance, predicting arrest as a proxy for criminal behavior. With this "label bias," one should exclude a feature if its correlation with the proxy and its correlation with the true outcome have opposite signs, conditional on the other model features. This criterion is often satisfied when a feature is weakly correlated with the true outcome, and, additionally, that feature and the true outcome are both direct causes of the proxy outcome. For example, criminal behavior and geography may be weakly correlated and, due to patterns of police deployment, direct causes of one's arrest record-suggesting that excluding geography in criminal risk assessment will weaken an algorithm's performance in predicting arrest but will improve its capacity to predict actual crime.
在设计风险评估算法时,许多学者推崇一种“一锅烩”的方法,理由是更多信息能带来更准确的预测。然而,我们发现,当算法被训练用于预测真实结果的替代指标时,例如将被捕作为犯罪行为的替代指标进行预测,这种基本原理往往会失效。存在这种“标签偏差”时,如果一个特征与替代指标的相关性以及与真实结果的相关性具有相反的符号,且以其他模型特征为条件,那么就应该排除该特征。当一个特征与真实结果弱相关,并且该特征和真实结果都是替代结果的直接原因时,这个标准通常会得到满足。例如,犯罪行为和地理位置可能弱相关,并且由于警察部署模式的原因,它们都是一个人被捕记录的直接原因——这表明在犯罪风险评估中排除地理位置会削弱算法预测被捕的性能,但会提高其预测实际犯罪的能力。