Division of Infection and Immunity, University College London, London WC1E 6BT, United Kingdom.
Institute for the Physics of Living Systems, University College London, London WC1E 6BT, United Kingdom.
Proc Natl Acad Sci U S A. 2024 Oct 15;121(42):e2408696121. doi: 10.1073/pnas.2408696121. Epub 2024 Oct 7.
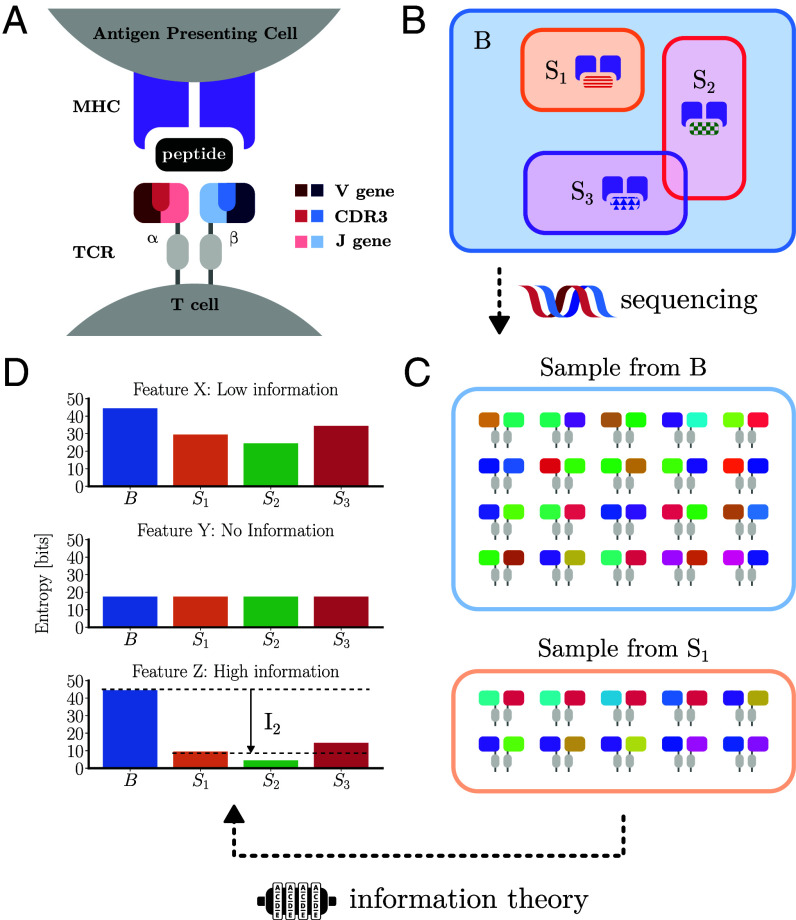
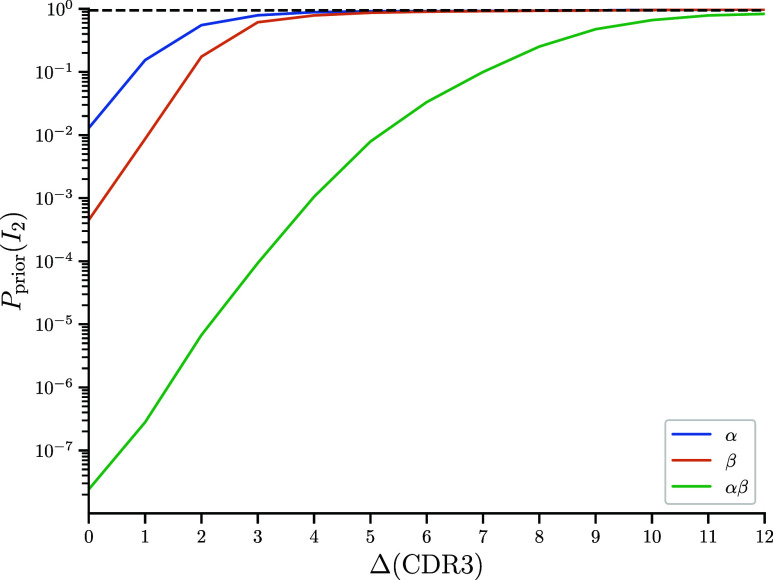
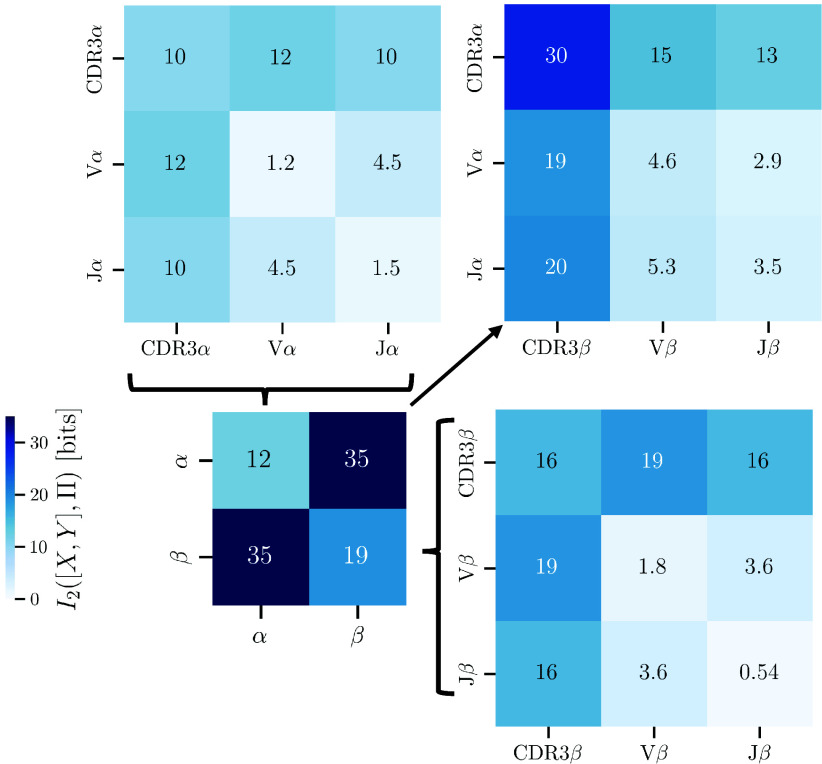
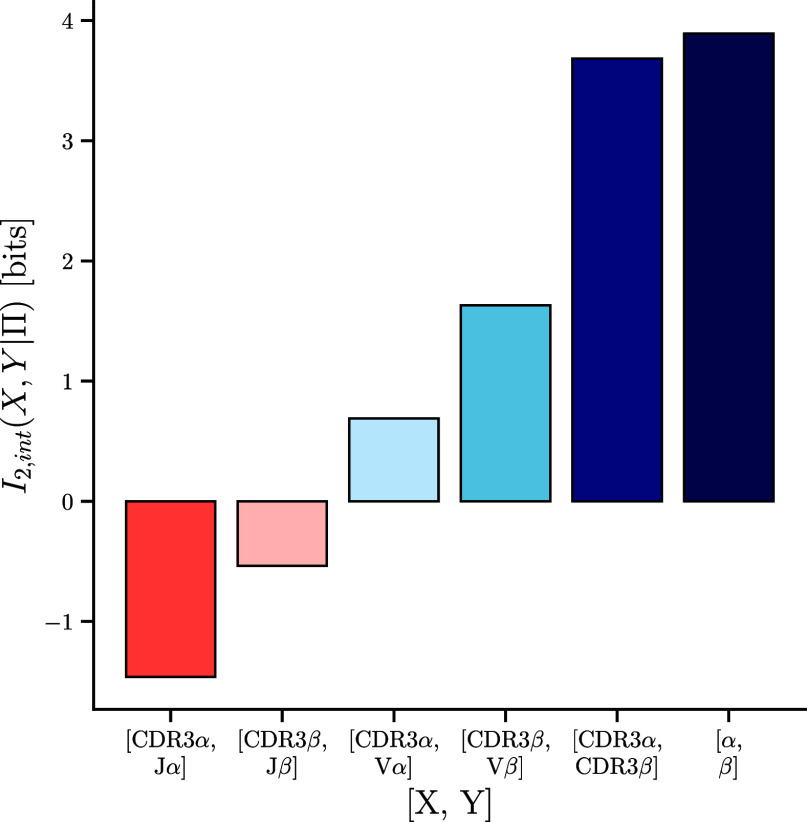
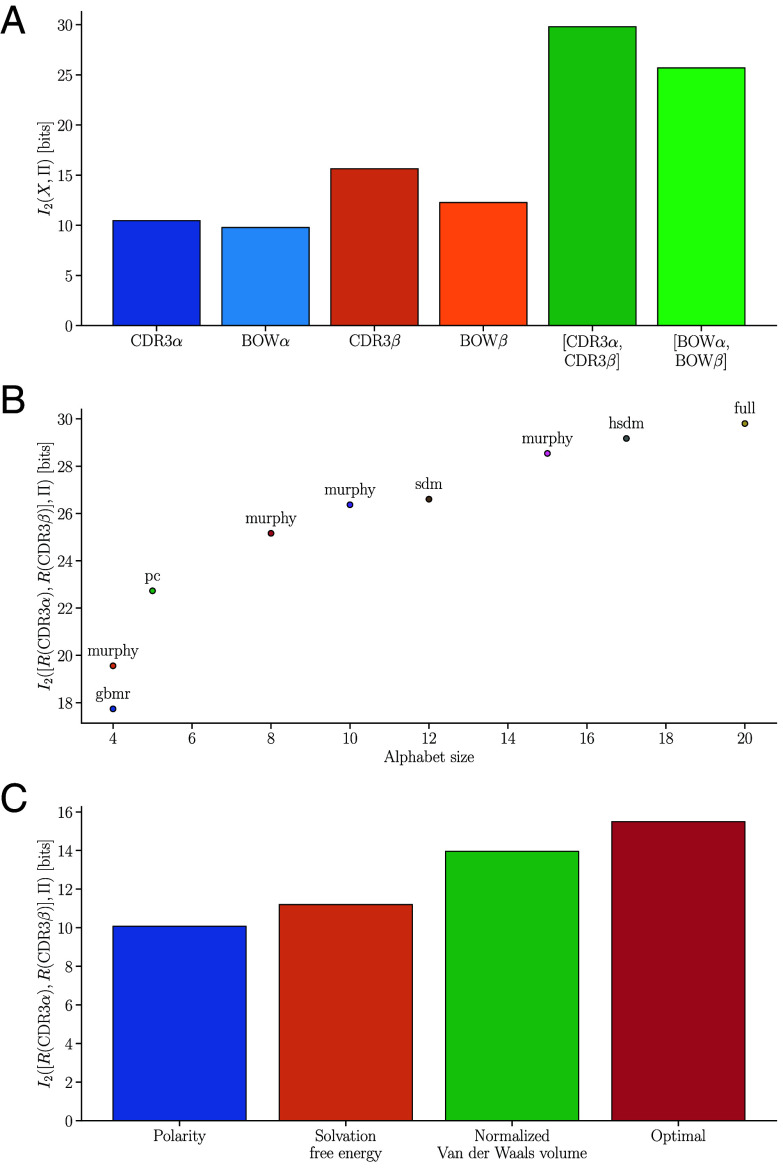
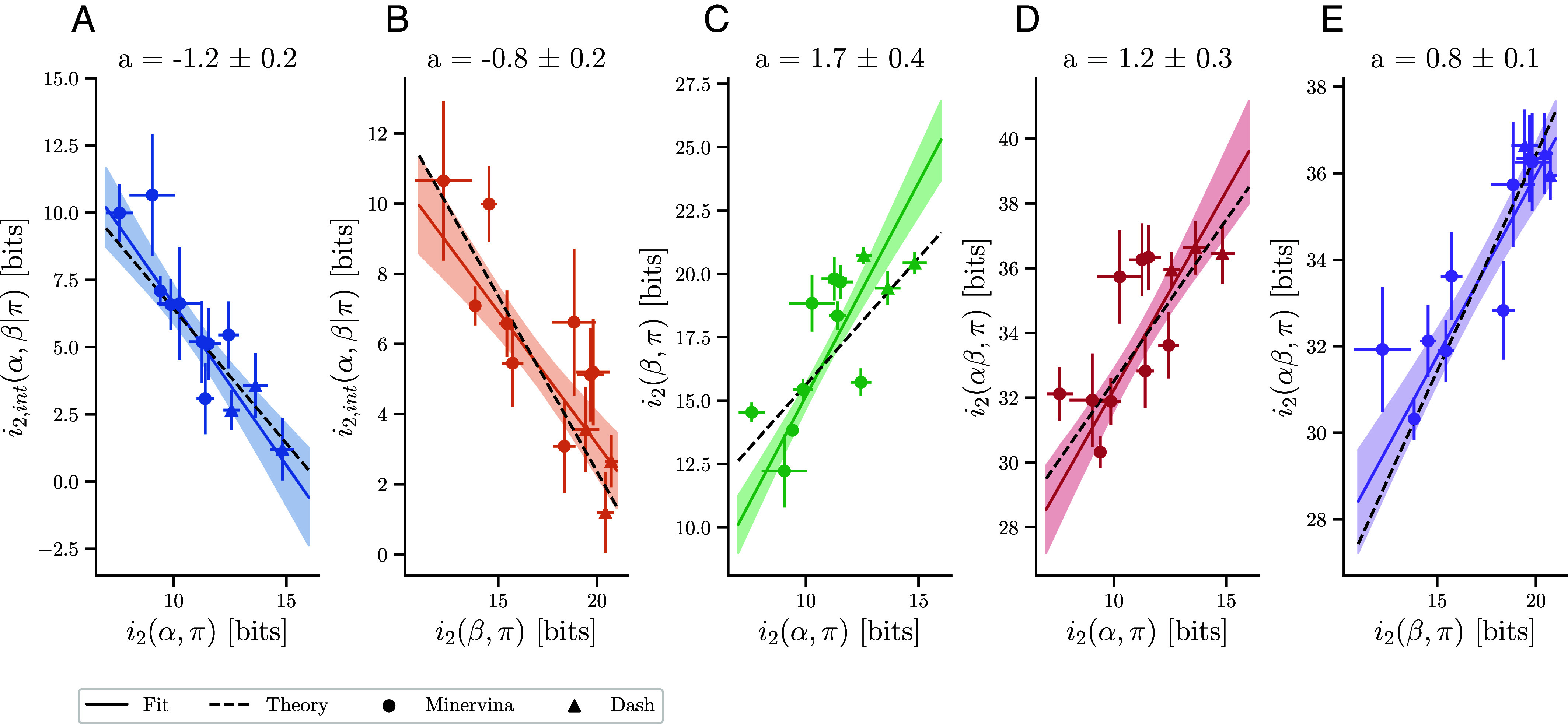
A key challenge in molecular biology is to decipher the mapping of protein sequence to function. To perform this mapping requires the identification of sequence features most informative about function. Here, we quantify the amount of information (in bits) that T cell receptor (TCR) sequence features provide about antigen specificity. We identify informative features by their degree of conservation among antigen-specific receptors relative to null expectations. We find that TCR specificity synergistically depends on the hypervariable regions of both receptor chains, with a degree of synergy that strongly depends on the ligand. Using a coincidence-based approach to measuring information enables us to directly bound the accuracy with which TCR specificity can be predicted from partial matches to reference sequences. We anticipate that our statistical framework will be of use for developing machine learning models for TCR specificity prediction and for optimizing TCRs for cell therapies. The proposed coincidence-based information measures might find further applications in bounding the performance of pairwise classifiers in other fields.
分子生物学的一个关键挑战是破译蛋白质序列与功能的映射。要进行这种映射,需要确定对功能最具信息量的序列特征。在这里,我们量化了 T 细胞受体 (TCR) 序列特征提供关于抗原特异性的信息量(以位为单位)。我们通过相对于空值预期的抗原特异性受体之间的序列特征的保守程度来识别信息特征。我们发现 TCR 特异性协同地依赖于受体链的两个超变区,协同程度强烈依赖于配体。使用基于巧合的方法来测量信息,使我们能够直接确定从参考序列的部分匹配中预测 TCR 特异性的准确性。我们预计,我们的统计框架将有助于开发用于预测 TCR 特异性的机器学习模型,并优化用于细胞治疗的 TCR。所提出的基于巧合的信息度量可能会在其他领域中用于限制成对分类器的性能。