Department of Computer Science and Engineering, Université du Québec en Outaouais, Gatineau, QC J8Y 3G5, Canada.
Sensors (Basel). 2017 Jun 7;17(6):1287. doi: 10.3390/s17061287.
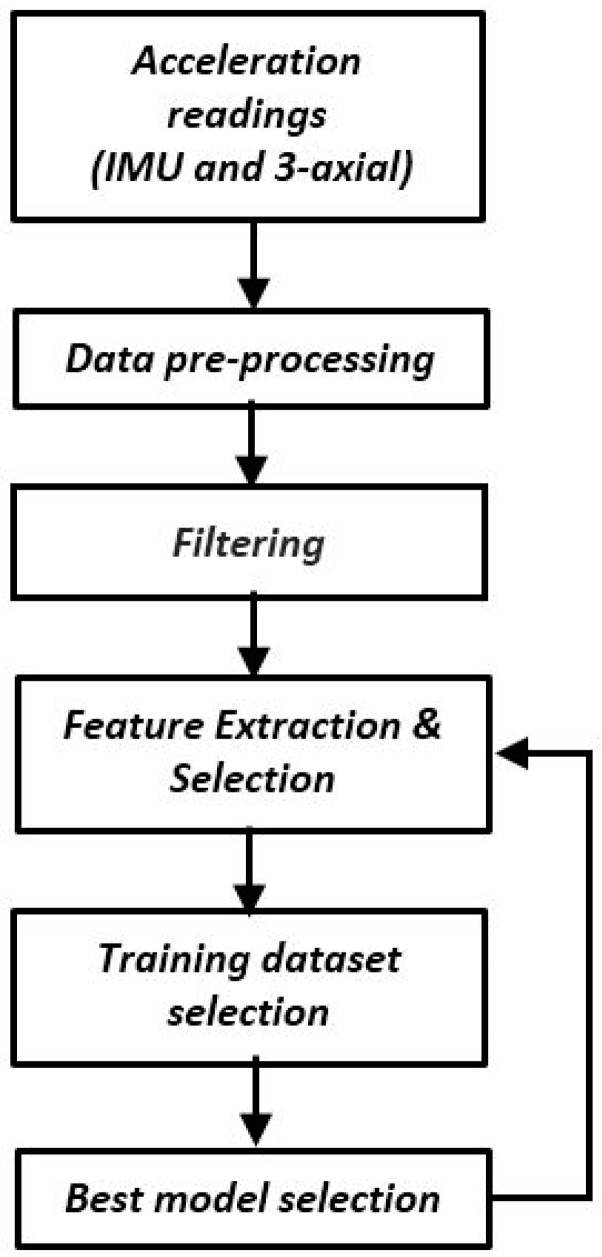
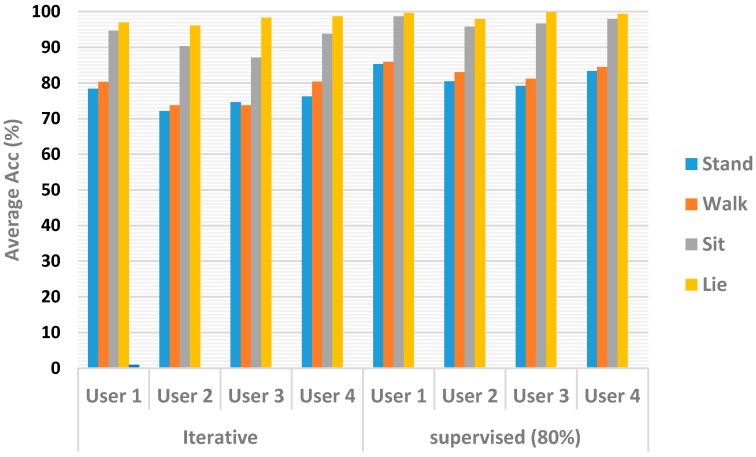
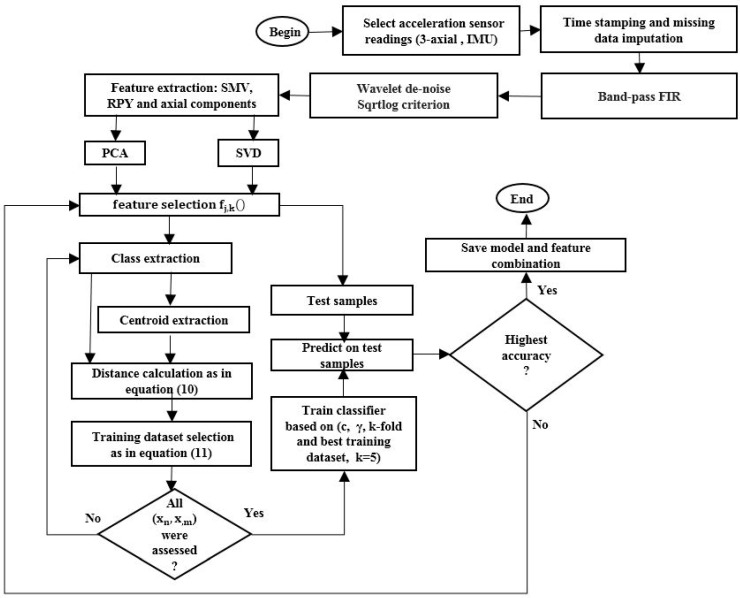
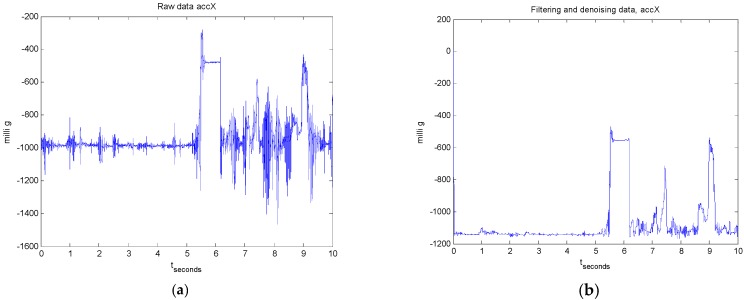
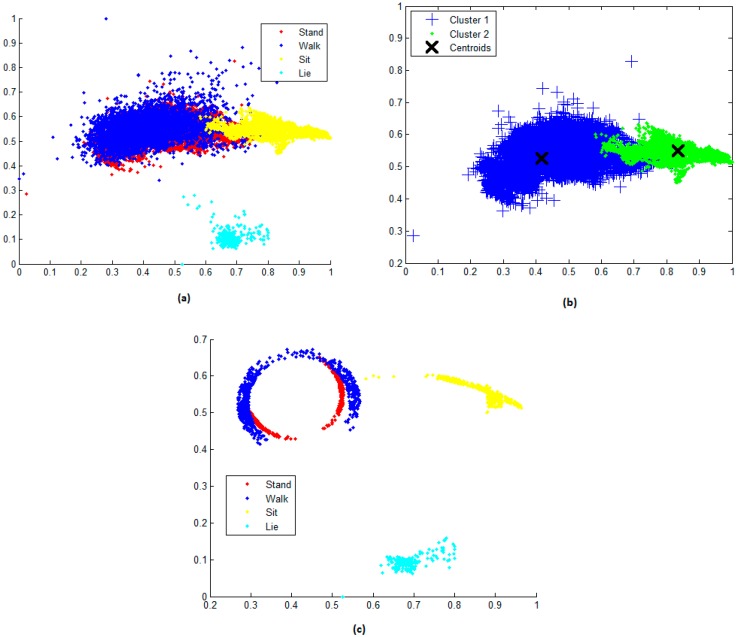
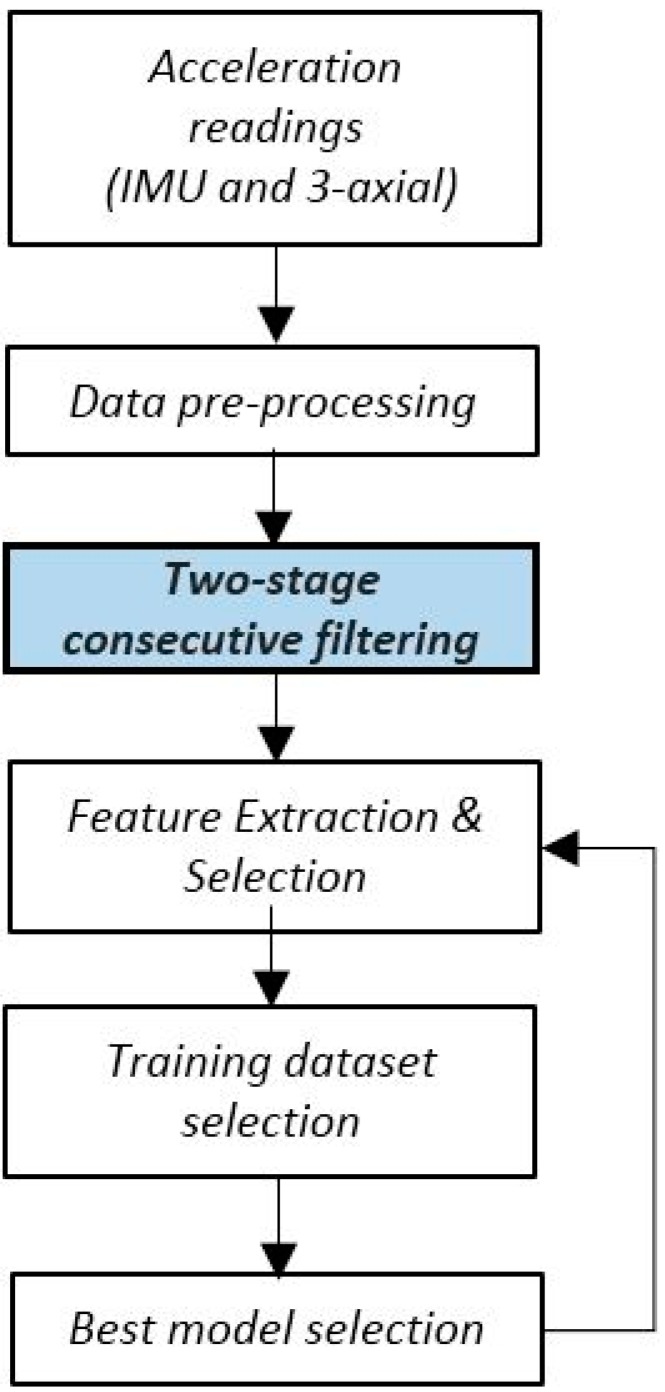
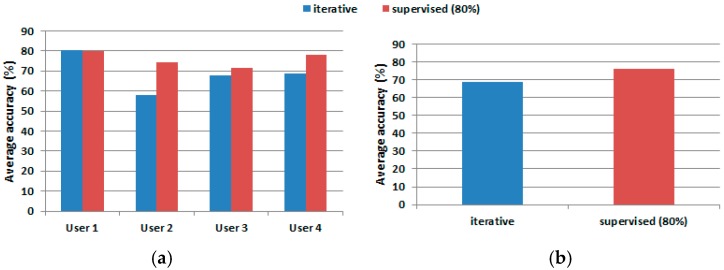
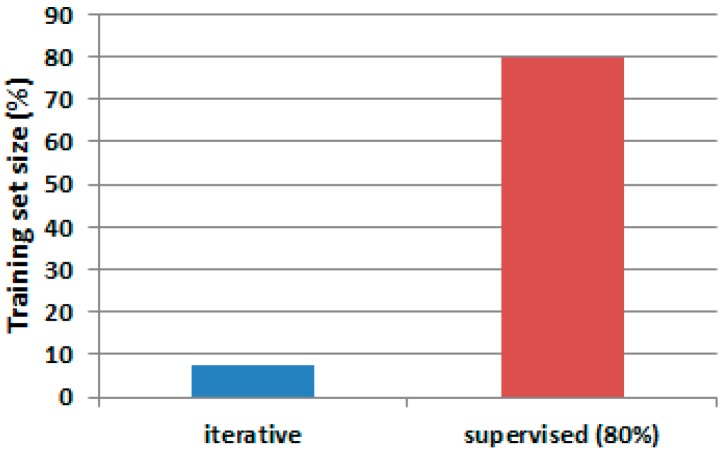
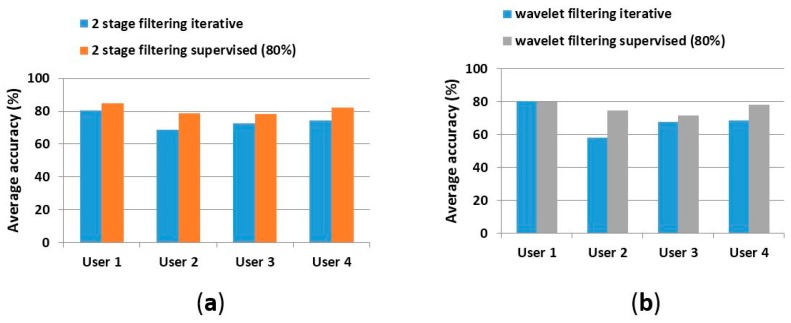
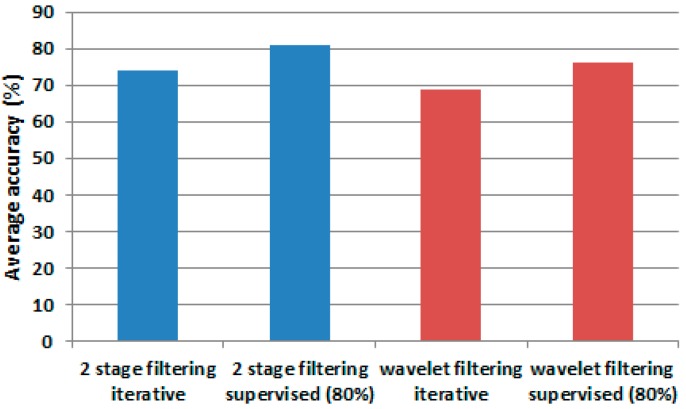
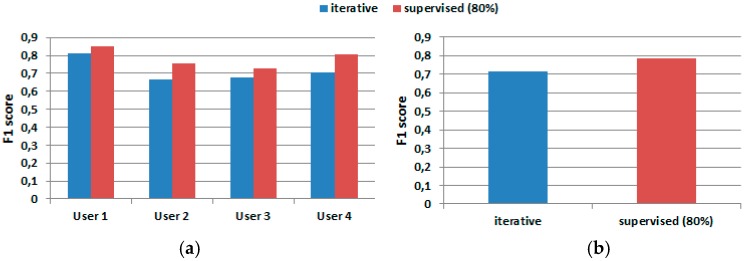
The design of multiple human activity recognition applications in areas such as healthcare, sports and safety relies on wearable sensor technologies. However, when making decisions based on the data acquired by such sensors in practical situations, several factors related to sensor data alignment, data losses, and noise, among other experimental constraints, deteriorate data quality and model accuracy. To tackle these issues, this paper presents a data-driven iterative learning framework to classify human locomotion activities such as walk, stand, lie, and sit, extracted from the Opportunity dataset. Data acquired by twelve 3-axial acceleration sensors and seven inertial measurement units are initially de-noised using a two-stage consecutive filtering approach combining a band-pass Finite Impulse Response (FIR) and a wavelet filter. A series of statistical parameters are extracted from the kinematical features, including the principal components and singular value decomposition of roll, pitch, yaw and the norm of the axial components. The novel interactive learning procedure is then applied in order to minimize the number of samples required to classify human locomotion activities. Only those samples that are most distant from the centroids of data clusters, according to a measure presented in the paper, are selected as candidates for the training dataset. The newly built dataset is then used to train an SVM multi-class classifier. The latter will produce the lowest prediction error. The proposed learning framework ensures a high level of robustness to variations in the quality of input data, while only using a much lower number of training samples and therefore a much shorter training time, which is an important consideration given the large size of the dataset.
多个人类活动识别应用程序的设计,如医疗保健、运动和安全等,都依赖于可穿戴传感器技术。然而,当基于这些传感器在实际情况下获取的数据做出决策时,与传感器数据对齐、数据丢失和噪声等实验限制相关的几个因素会降低数据质量和模型准确性。为了解决这些问题,本文提出了一种数据驱动的迭代学习框架,用于对从机会数据集提取的人类运动活动(如行走、站立、躺卧和坐下)进行分类。最初,使用结合了带通有限脉冲响应(FIR)滤波器和小波滤波器的两级连续滤波方法对来自 12 个三轴加速度传感器和 7 个惯性测量单元的数据进行去噪。从运动学特征中提取了一系列统计参数,包括滚动、俯仰、偏航的主成分和奇异值分解,以及轴向分量的范数。然后应用新的交互学习过程来最小化分类人类运动活动所需的样本数量。根据本文提出的度量标准,只有那些与数据簇质心最远的样本才被选为训练数据集的候选样本。然后使用新构建的数据集来训练 SVM 多类分类器。后者将产生最低的预测误差。所提出的学习框架确保了对输入数据质量变化的高度鲁棒性,同时只使用了更少数量的训练样本,因此训练时间更短,这在考虑到数据集的大型规模时非常重要。