Dutta Sourav, Schafer Clemens, Gomez Jorge, Ni Kai, Joshi Siddharth, Datta Suman
Department of Electrical Engineering, College of Engineering, University of Notre Dame, Notre Dame, IN, United States.
Department of Computer Science and Engineering, College of Engineering, University of Notre Dame, Notre Dame, IN, United States.
Front Neurosci. 2020 Jun 24;14:634. doi: 10.3389/fnins.2020.00634. eCollection 2020.
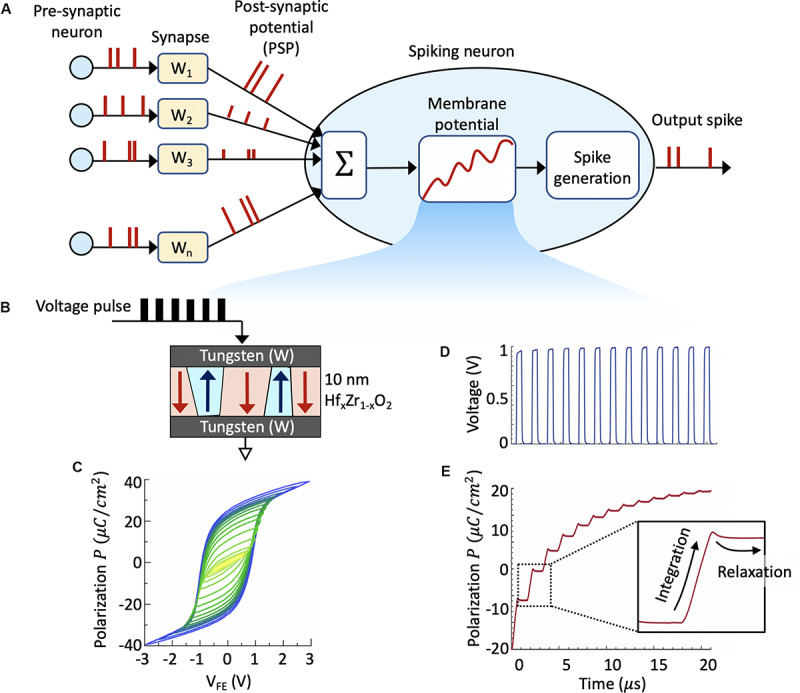
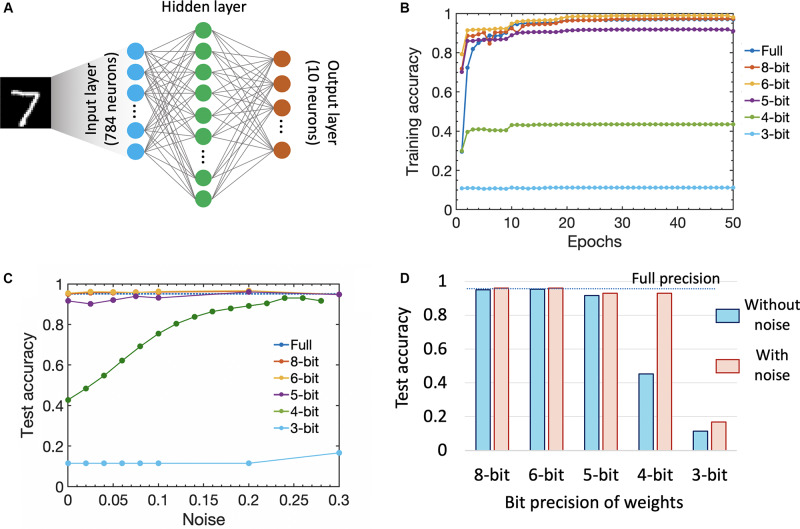
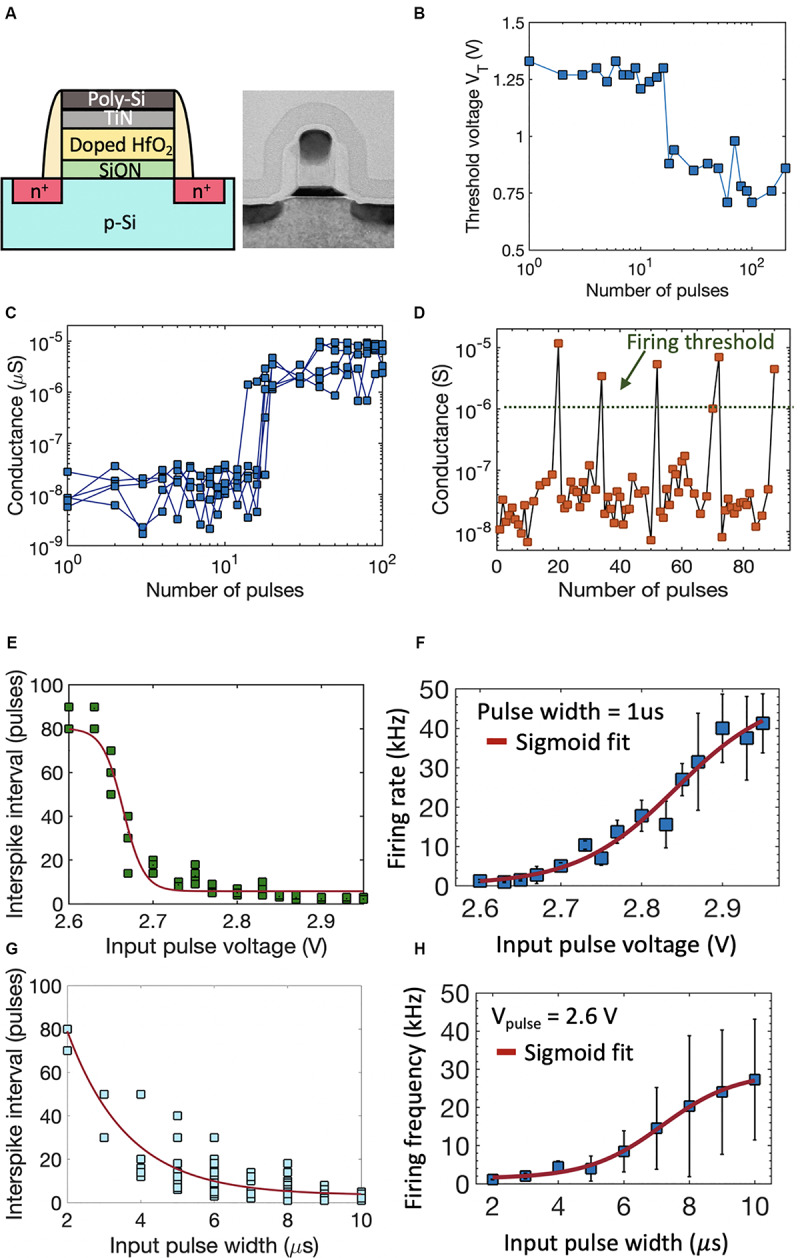
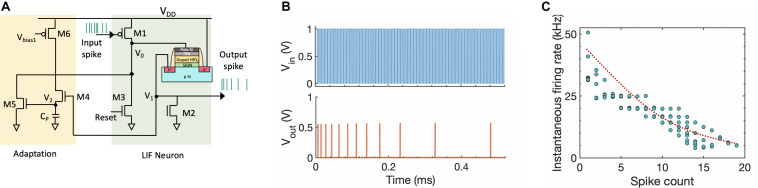
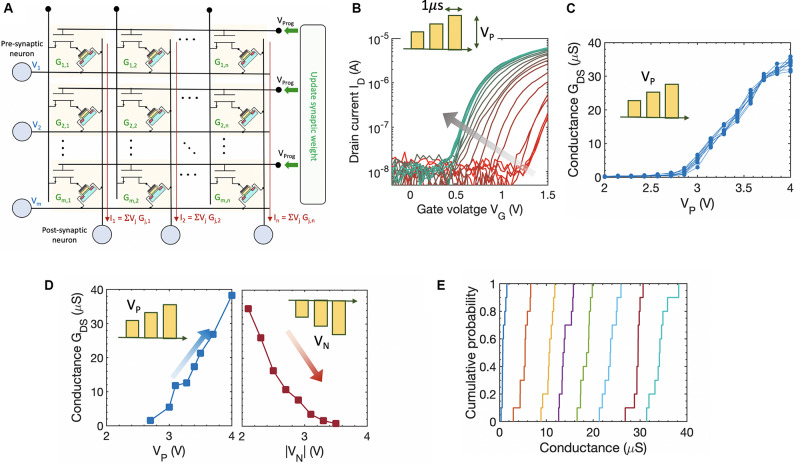
The two possible pathways toward artificial intelligence (AI)-(i) neuroscience-oriented neuromorphic computing [like spiking neural network (SNN)] and (ii) computer science driven machine learning (like deep learning) differ widely in their fundamental formalism and coding schemes (Pei et al., 2019). Deviating from traditional deep learning approach of relying on neuronal models with static nonlinearities, SNNs attempt to capture brain-like features like computation using spikes. This holds the promise of improving the energy efficiency of the computing platforms. In order to achieve a much higher areal and energy efficiency compared to today's hardware implementation of SNN, we need to go beyond the traditional route of relying on CMOS-based digital or mixed-signal neuronal circuits and segregation of computation and memory under the von Neumann architecture. Recently, ferroelectric field-effect transistors (FeFETs) are being explored as a promising alternative for building neuromorphic hardware by utilizing their non-volatile nature and rich polarization switching dynamics. In this work, we propose an all FeFET-based SNN hardware that allows low-power spike-based information processing and co-localized memory and computing (a.k.a. in-memory computing). We experimentally demonstrate the essential neuronal and synaptic dynamics in a 28 nm high-K metal gate FeFET technology. Furthermore, drawing inspiration from the traditional machine learning approach of optimizing a cost function to adjust the synaptic weights, we implement a surrogate gradient (SG) learning algorithm on our SNN platform that allows us to perform supervised learning on MNIST dataset. As such, we provide a pathway toward building energy-efficient neuromorphic hardware that can support traditional machine learning algorithms. Finally, we undertake synergistic device-algorithm co-design by accounting for the impacts of device-level variation (stochasticity) and limited bit precision of on-chip synaptic weights (available analog states) on the classification accuracy.
通往人工智能(AI)的两条可能途径——(i)面向神经科学的神经形态计算[如脉冲神经网络(SNN)]和(ii)计算机科学驱动的机器学习(如深度学习)——在其基本形式和编码方案上有很大差异(裴等人,2019年)。与依赖具有静态非线性的神经元模型的传统深度学习方法不同,SNN试图利用脉冲来捕捉类似大脑的特征,如计算。这有望提高计算平台的能源效率。为了实现比当今SNN的硬件实现更高的面积效率和能源效率,我们需要超越依赖基于CMOS的数字或混合信号神经元电路以及冯·诺依曼架构下计算与存储分离的传统途径。最近,铁电场效应晶体管(FeFET)因其非易失性和丰富的极化切换动力学,正被探索作为构建神经形态硬件的一种有前景的替代方案。在这项工作中,我们提出了一种全基于FeFET的SNN硬件,它允许基于低功耗脉冲的信息处理以及共定位的存储和计算(即内存计算)。我们通过实验证明了在28纳米高K金属栅FeFET技术中的基本神经元和突触动力学。此外,从优化成本函数以调整突触权重的传统机器学习方法中获得灵感,我们在我们的SNN平台上实现了一种替代梯度(SG)学习算法,使我们能够在MNIST数据集上进行监督学习。因此,我们提供了一条构建能够支持传统机器学习算法的节能神经形态硬件的途径。最后,我们通过考虑器件级变化(随机性)和片上突触权重的有限位精度(可用模拟状态)对分类精度的影响,进行了协同器件 - 算法协同设计。