Department of Computer Engineering and Automation, Federal University of Rio Grande do Norte, Natal 59078-970, RN, Brazil.
Department of Computer Science, Federal Institute of Rio Grande do Norte, Mossoro 59628-330, RN, Brazil.
Int J Environ Res Public Health. 2020 Jul 15;17(14):5115. doi: 10.3390/ijerph17145115.
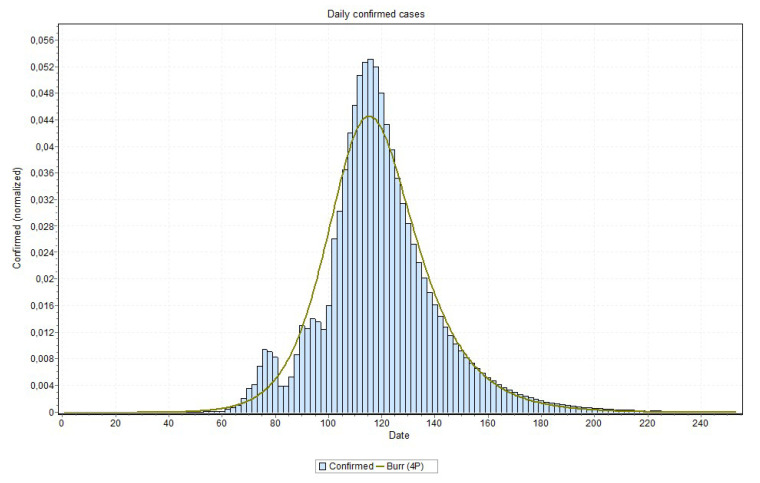
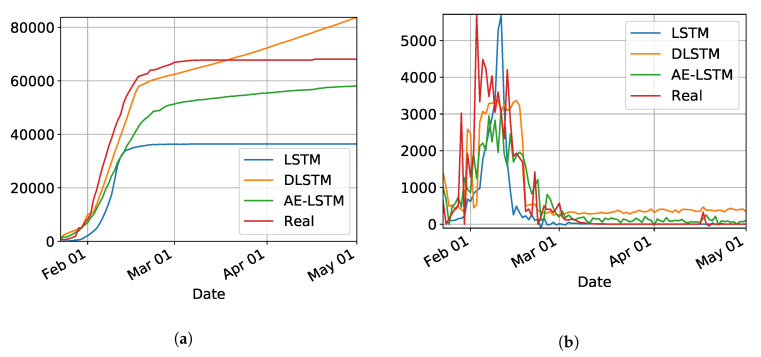
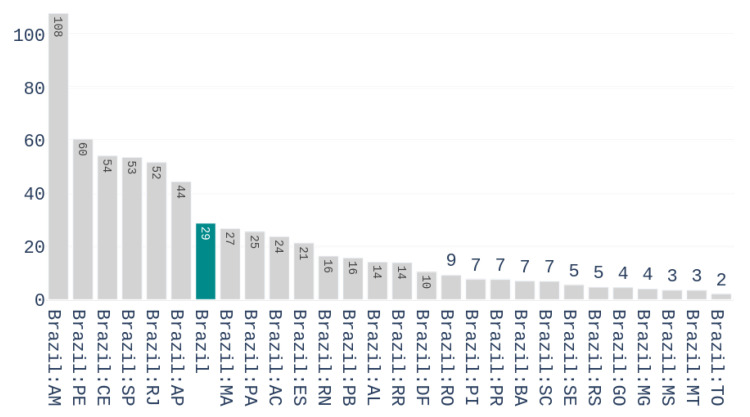
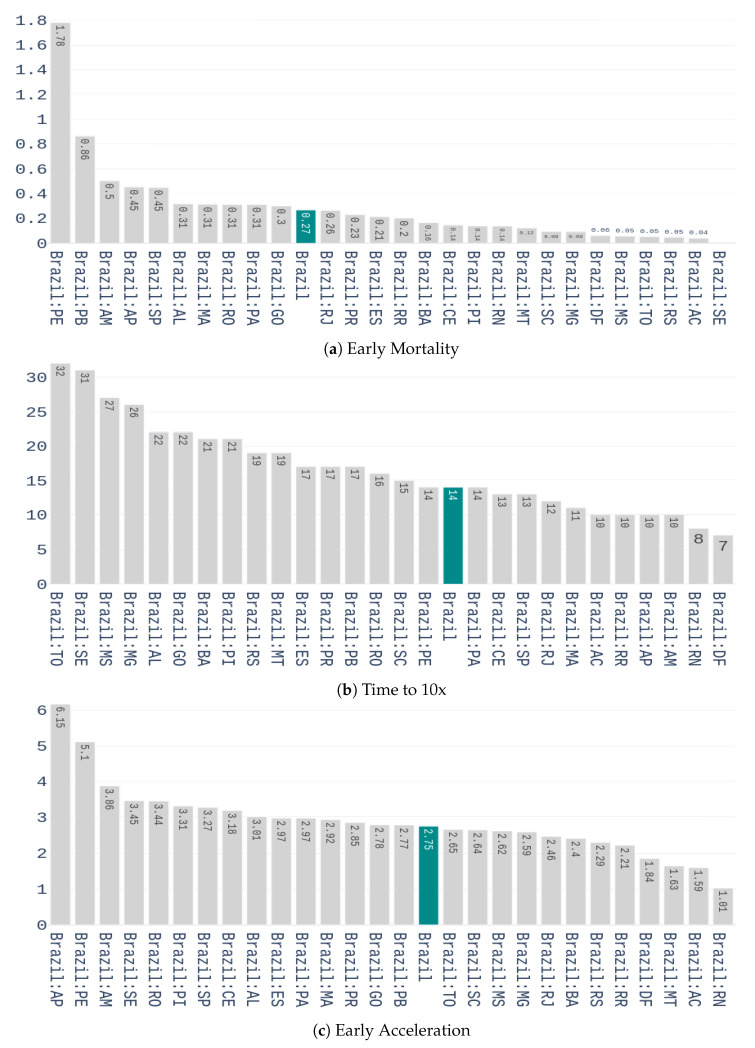
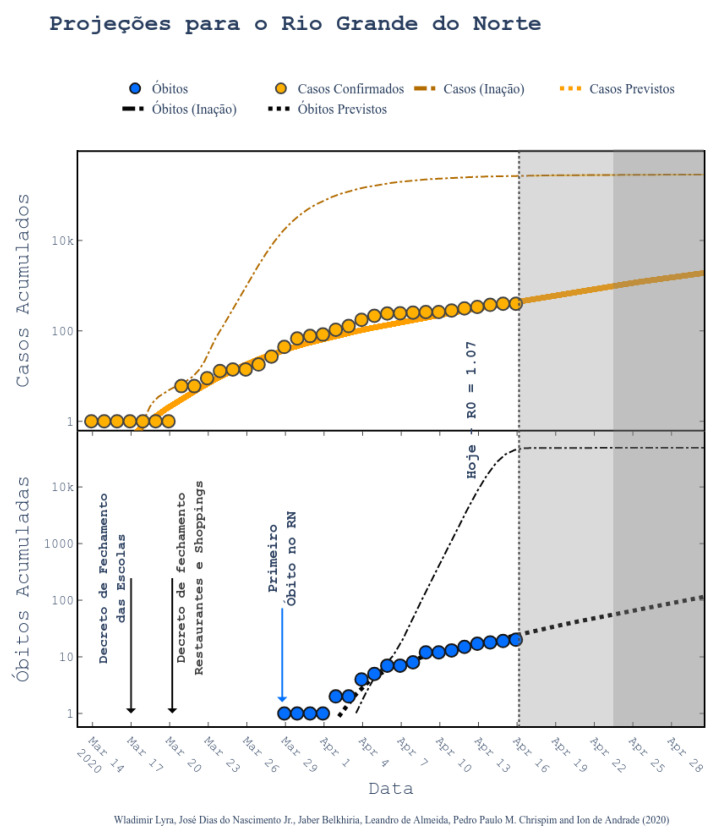
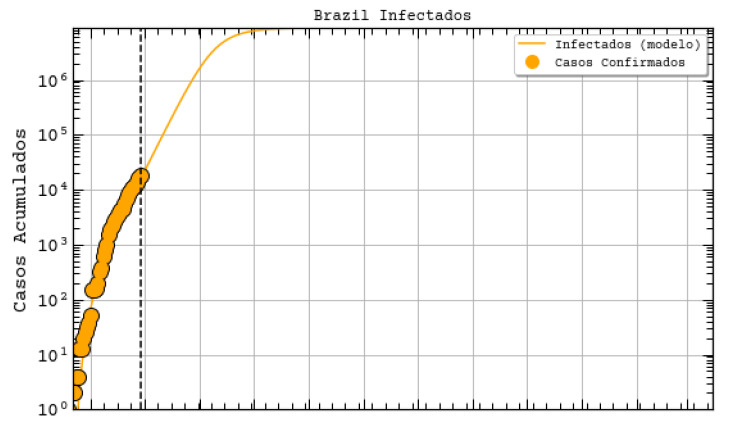
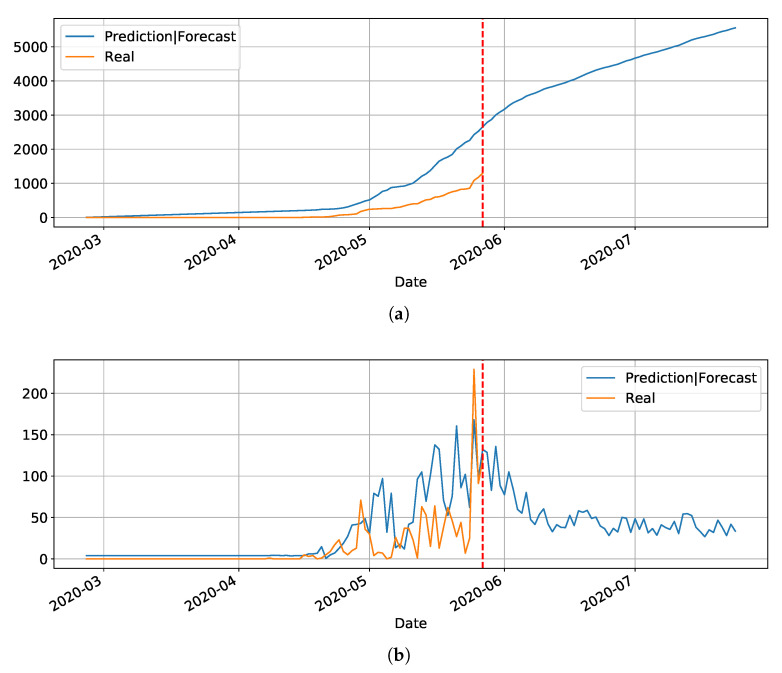
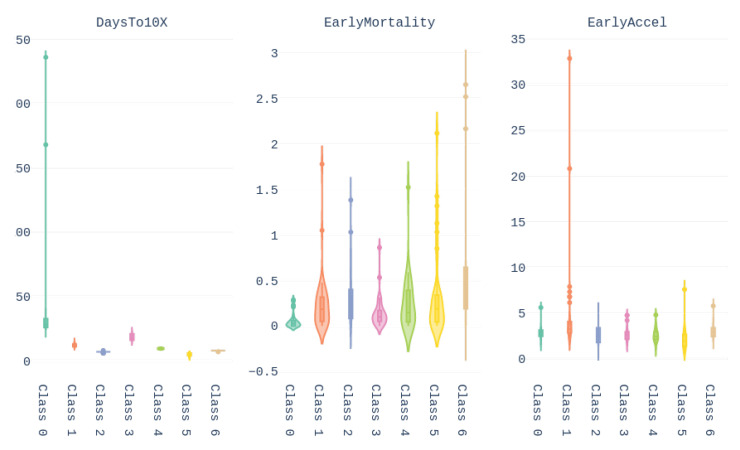
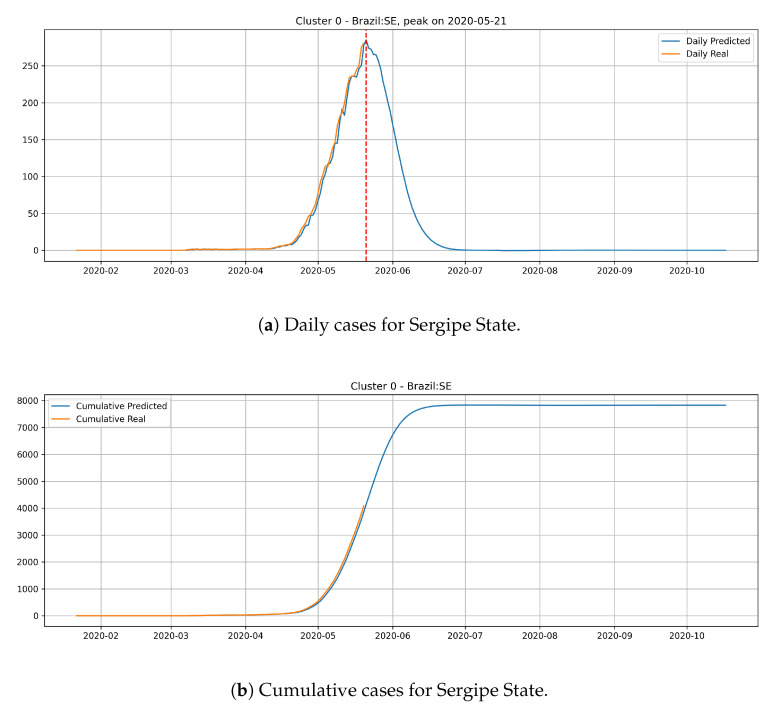
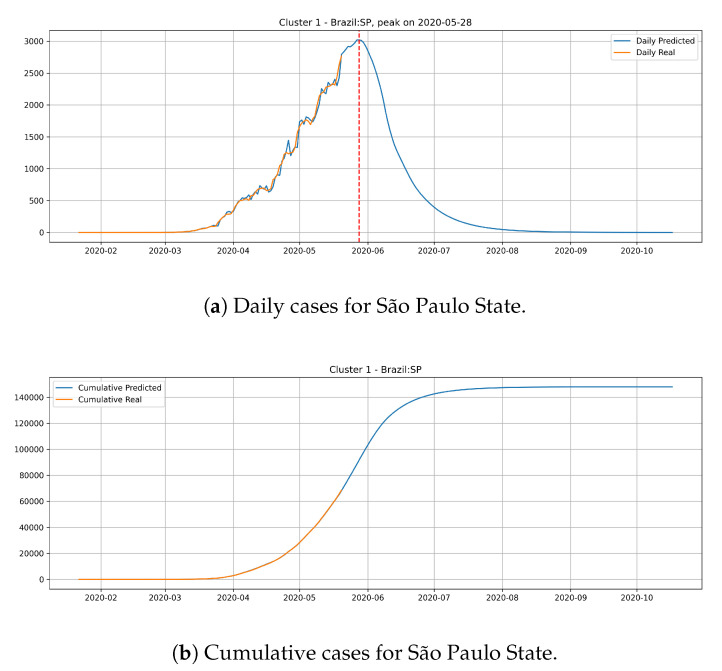
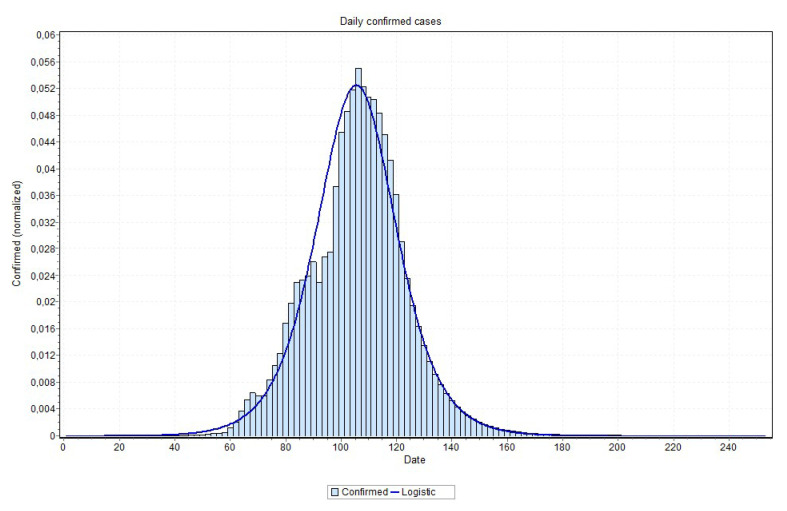
The contribution of this paper is twofold. First, a new data driven approach for predicting the Covid-19 pandemic dynamics is introduced. The second contribution consists in reporting and discussing the results that were obtained with this approach for the Brazilian states, with predictions starting as of 4 May 2020. As a preliminary study, we first used an Long Short Term Memory for Data Training-SAE (LSTM-SAE) network model. Although this first approach led to somewhat disappointing results, it served as a good baseline for testing other ANN types. Subsequently, in order to identify relevant countries and regions to be used for training ANN models, we conduct a clustering of the world's regions where the pandemic is at an advanced stage. This clustering is based on manually engineered features representing a country's response to the early spread of the pandemic, and the different clusters obtained are used to select the relevant countries for training the models. The final models retained are Modified Auto-Encoder networks, that are trained on these clusters and learn to predict future data for Brazilian states. These predictions are used to estimate important statistics about the disease, such as peaks and number of confirmed cases. Finally, curve fitting is carried out to find the distribution that best fits the outputs of the MAE, and to refine the estimates of the peaks of the pandemic. Predicted numbers reach a total of more than one million infected Brazilians, distributed among the different states, with São Paulo leading with about 150 thousand confirmed cases predicted. The results indicate that the pandemic is still growing in Brazil, with most states peaks of infection estimated in the second half of May 2020. The estimated end of the pandemics (97% of cases reaching an outcome) spread between June and the end of August 2020, depending on the states.
本文的贡献有两点。首先,提出了一种新的数据驱动方法来预测新冠疫情动态。第二个贡献是报告和讨论了该方法在巴西各州的预测结果,预测始于 2020 年 5 月 4 日。作为初步研究,我们首先使用了长短期记忆数据训练 - 自编码器(LSTM-SAE)网络模型。尽管这种最初的方法导致了一些令人失望的结果,但它为测试其他 ANN 类型提供了一个良好的基线。随后,为了确定可用于训练 ANN 模型的相关国家和地区,我们对疫情处于高级阶段的世界各地区进行了聚类。这种聚类是基于代表国家对疫情早期传播的反应的手动设计特征,获得的不同聚类用于选择相关国家进行模型训练。最终保留的模型是修改后的自动编码器网络,它们在这些聚类上进行训练,以学习预测巴西各州的未来数据。这些预测用于估计疾病的重要统计数据,例如峰值和确诊病例数。最后,进行曲线拟合以找到最适合 MAE 输出的分布,并改进疫情峰值的估计。预测的数字达到了超过 100 万的感染巴西人,分布在不同的州,圣保罗州预计有 15 万例确诊病例。结果表明,疫情在巴西仍在蔓延,大多数州的感染高峰期预计在 2020 年 5 月下旬。预计疫情结束(97%的病例达到结局)的时间在 6 月至 8 月底之间,具体取决于各州。