School of Basic Sciences, EPFL, Lausanne, Switzerland.
Merck Institute for Pharmacometrics (an affiliate of Merck KGaA, Darmstadt, Germany), Lausanne, Switzerland.
J Pharmacokinet Pharmacodyn. 2022 Apr;49(2):257-270. doi: 10.1007/s10928-021-09793-6. Epub 2021 Oct 27.
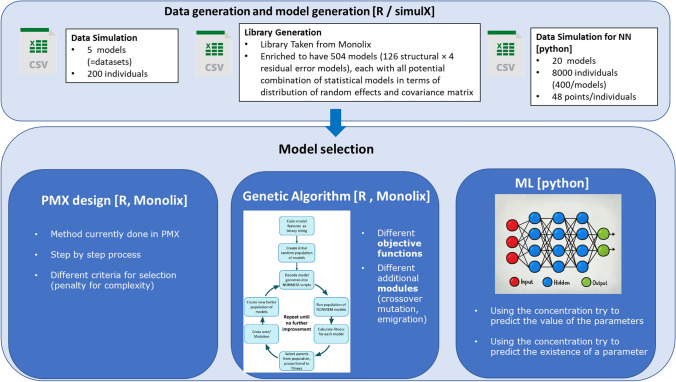
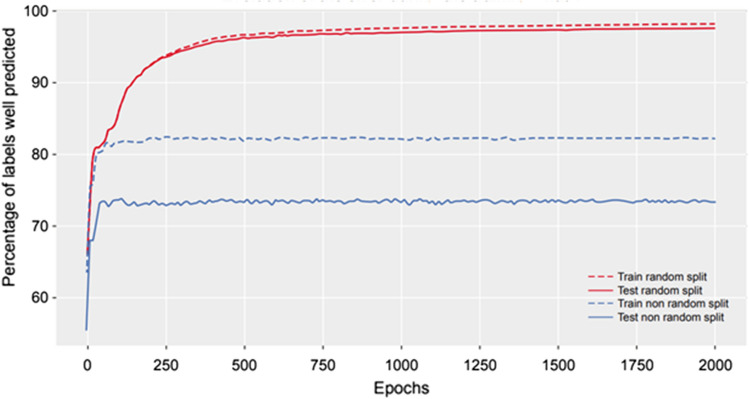
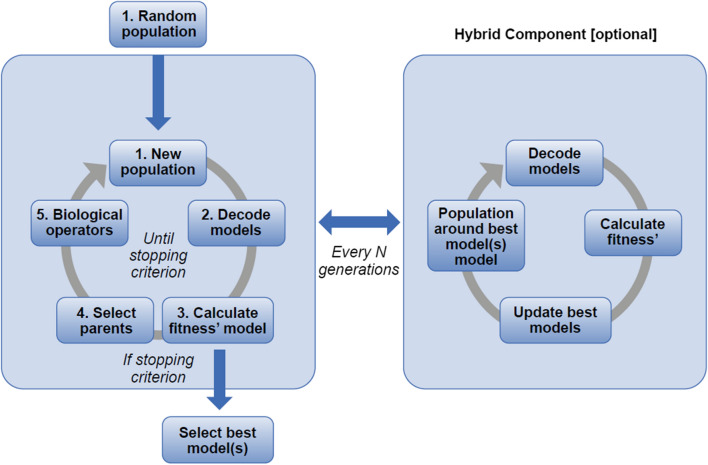
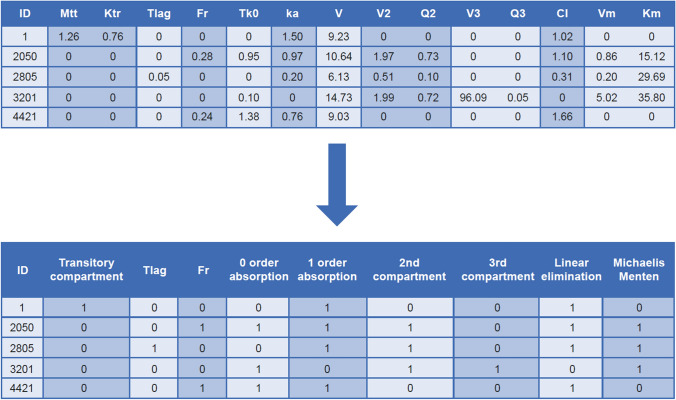
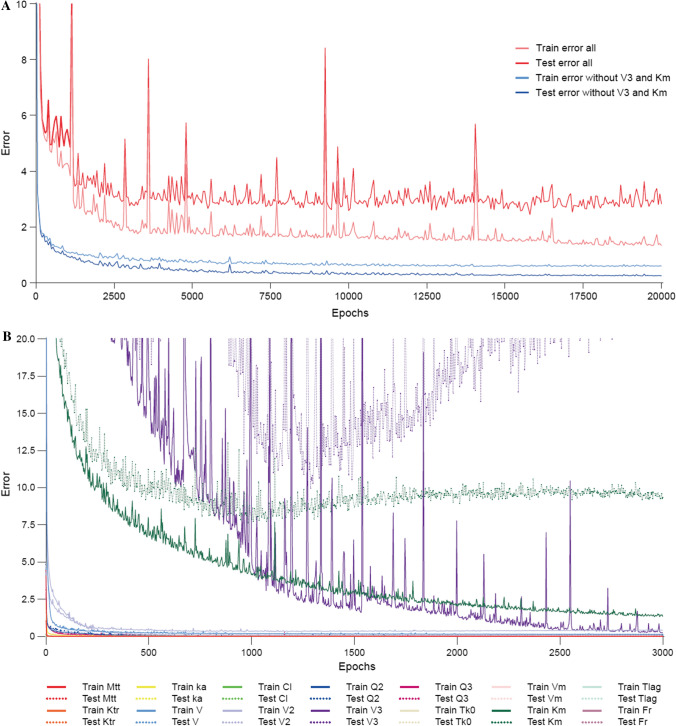
A fit-for-purpose structural and statistical model is the first major requirement in population pharmacometric model development. In this manuscript we discuss how this complex and computationally intensive task could benefit from supervised machine learning algorithms. We compared the classical pharmacometric approach with two machine learning methods, genetic algorithm and neural networks, in different scenarios based on simulated pharmacokinetic data. Genetic algorithm performance was assessed using a fitness function based on log-likelihood, whilst neural networks were trained using mean square error or binary cross-entropy loss. Machine learning provided a selection based only on statistical rules and achieved accurate selection. The minimization process of genetic algorithm was successful at allowing the algorithm to select plausible models. Neural network classification tasks achieved the most accurate results. Neural network regression tasks were less precise than neural network classification and genetic algorithm methods. The computational gain obtained by using machine learning was substantial, especially in the case of neural networks. We demonstrated that machine learning methods can greatly increase the efficiency of pharmacokinetic population model selection in case of large datasets or complex models requiring long run-times. Our results suggest that machine learning approaches can achieve a first fast selection of models which can be followed by more conventional pharmacometric approaches.
适合目的的结构和统计模型是群体药代动力学模型开发的首要要求。在本文中,我们讨论了复杂且计算密集型的任务如何受益于有监督的机器学习算法。我们基于模拟药代动力学数据,在不同场景下将经典的药代动力学方法与两种机器学习方法(遗传算法和神经网络)进行了比较。遗传算法的性能使用基于对数似然的拟合函数进行评估,而神经网络则使用均方误差或二进制交叉熵损失进行训练。机器学习仅基于统计规则进行选择,从而实现了准确的选择。遗传算法的最小化过程成功地允许算法选择合理的模型。神经网络分类任务实现了最准确的结果。神经网络回归任务不如神经网络分类和遗传算法方法精确。使用机器学习获得的计算增益非常大,尤其是在处理大数据集或需要长时间运行的复杂模型时。我们的结果表明,在大数据集或需要长时间运行的复杂模型的情况下,机器学习方法可以大大提高药代动力学群体模型选择的效率。我们的结果表明,机器学习方法可以快速选择模型,然后再采用更传统的药代动力学方法。