Plaza Stephen M, Clements Jody, Dolafi Tom, Umayam Lowell, Neubarth Nicole N, Scheffer Louis K, Berg Stuart
Janelia Research Campus, Howard Hughes Medical Institute, Ashburn, VA, United States.
Front Neuroinform. 2022 Jul 20;16:896292. doi: 10.3389/fninf.2022.896292. eCollection 2022.
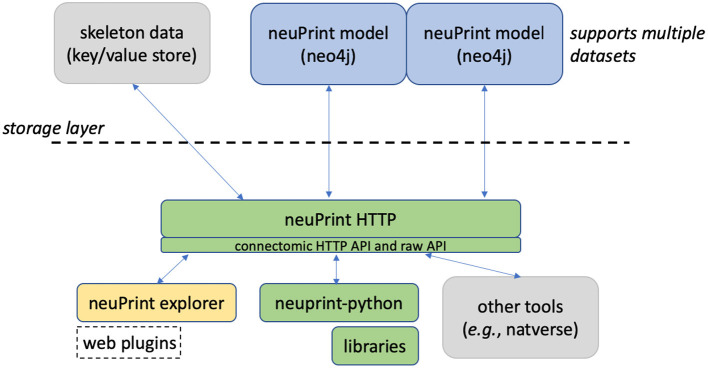
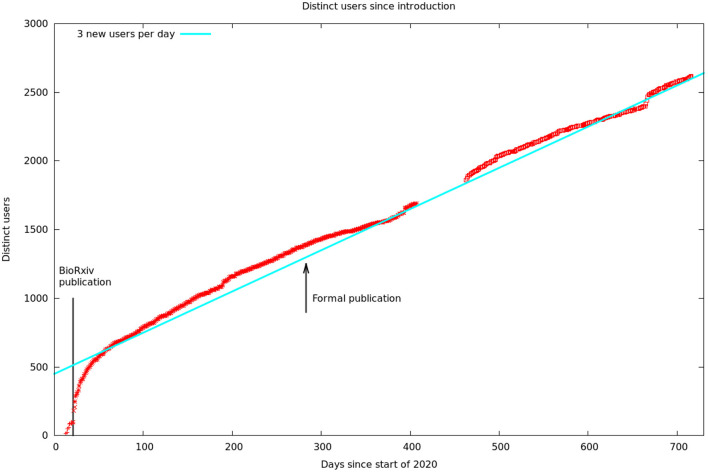
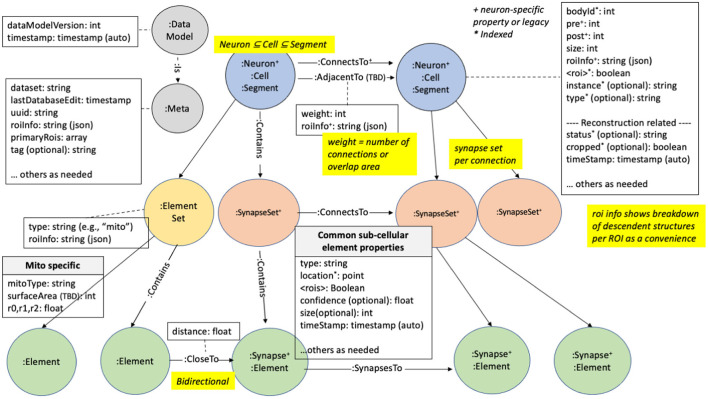
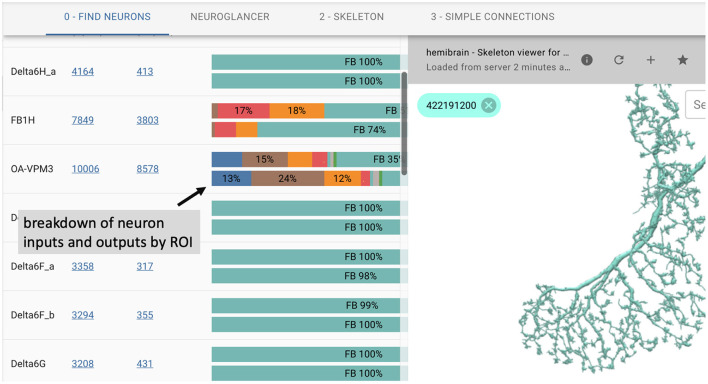
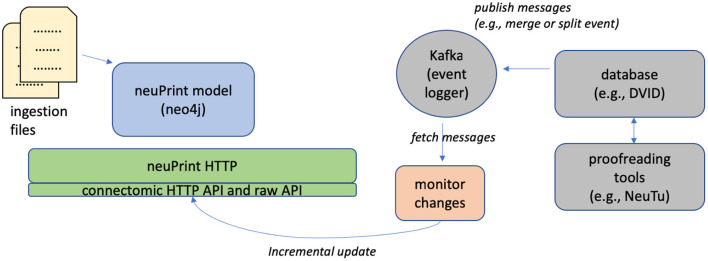
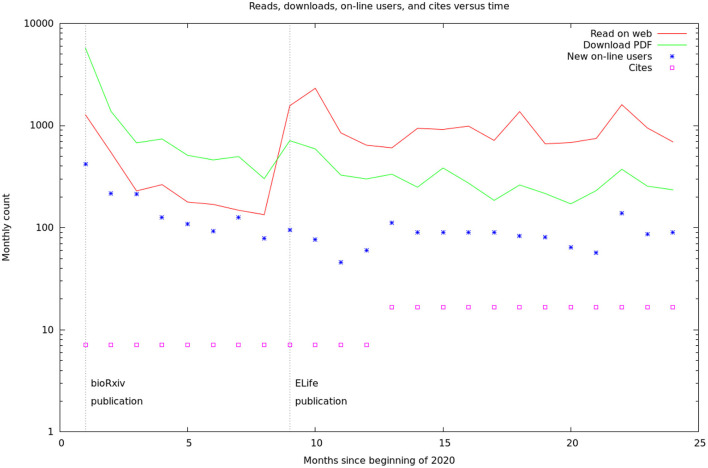
Due to advances in electron microscopy and deep learning, it is now practical to reconstruct a connectome, a description of neurons and the chemical synapses between them, for significant volumes of neural tissue. Smaller past reconstructions were primarily used by domain experts, could be handled by downloading data, and performance was not a serious problem. But new and much larger reconstructions upend these assumptions. These networks now contain tens of thousands of neurons and tens of millions of connections, with yet larger reconstructions pending, and are of interest to a large community of non-specialists. Allowing other scientists to make use of this data needs more than publication-it requires new tools that are publicly available, easy to use, and efficiently handle large data. We introduce neuPrint to address these data analysis challenges. Neuprint contains two major components-a web interface and programmer APIs. The web interface is designed to allow any scientist worldwide, using only a browser, to quickly ask and answer typical biological queries about a connectome. The neuPrint APIs allow more computer-savvy scientists to make more complex or higher volume queries. NeuPrint also provides features for assessing reconstruction quality. Internally, neuPrint organizes connectome data as a graph stored in a neo4j database. This gives high performance for typical queries, provides access though a public and well documented query language Cypher, and will extend well to future larger connectomics databases. Our experience is also an experiment in open science. We find a significant fraction of the readers of the article proceed to examine the data directly. In our case preprints worked exactly as intended, with data inquiries and PDF downloads starting immediately after pre-print publication, and little affected by formal publication later. From this we deduce that many readers are more interested in our data than in our analysis of our data, suggesting that data-only papers can be well appreciated and that public data release can speed up the propagation of scientific results by many months. We also find that providing, and keeping, the data available for online access imposes substantial additional costs to connectomics research.
由于电子显微镜技术和深度学习的进步,现在有可能为大量神经组织重建连接组,即对神经元及其之间的化学突触进行描述。过去较小规模的重建主要由领域专家使用,可以通过下载数据来处理,性能也不是严重问题。但新的、规模大得多的重建颠覆了这些假设。这些网络现在包含数万个神经元和数千万个连接,还有更大规模的重建正在进行中,并且受到广大非专业人士群体的关注。要让其他科学家利用这些数据,仅靠发表是不够的,还需要公开可用、易于使用且能有效处理大数据的新工具。我们引入neuPrint来应对这些数据分析挑战。NeuPrint包含两个主要组件——一个网络界面和程序员应用程序编程接口(API)。网络界面旨在让全球任何科学家仅通过浏览器就能快速提出并回答有关连接组的典型生物学问题。NeuPrint API允许更精通计算机的科学家进行更复杂或更高批量的查询。NeuPrint还提供评估重建质量的功能。在内部,NeuPrint将连接组数据组织为存储在neo4j数据库中的图形。这为典型查询提供了高性能,通过公开且文档完善的查询语言Cypher提供访问,并能很好地扩展到未来更大的连接组学数据库。我们的经验也是一次开放科学实验。我们发现相当一部分文章读者会直接去查看数据。就我们的情况而言,预印本的效果完全符合预期,预印本发表后立即开始有数据查询和PDF下载,且几乎不受后来正式发表的影响。由此我们推断,许多读者对我们的数据比对我们对数据的分析更感兴趣,这表明仅数据的论文也能得到很好的认可,并且公开数据发布可以将科学成果的传播速度加快数月。我们还发现,提供并保持数据可供在线访问给连接组学研究带来了大量额外成本。