Facultad de Telemática.
Departamento de Estadística, Universidad de Salamanca, c/Espejo 2, Salamanca, 37007, España.
G3 (Bethesda). 2019 May 7;9(5):1545-1556. doi: 10.1534/g3.119.300585.
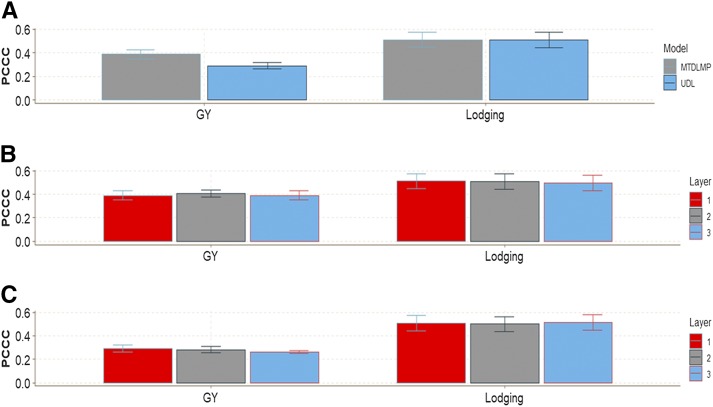
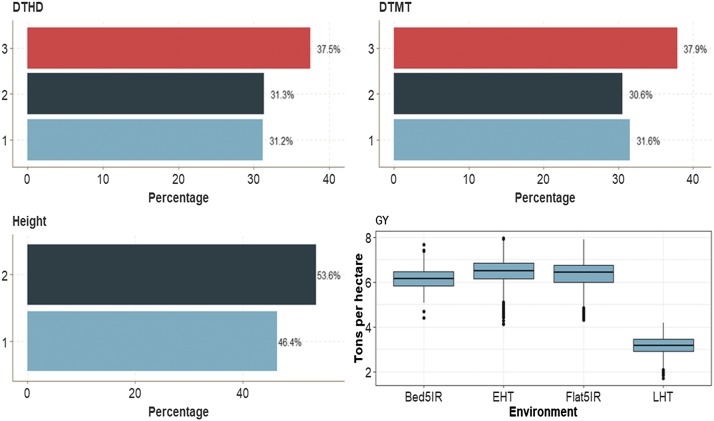
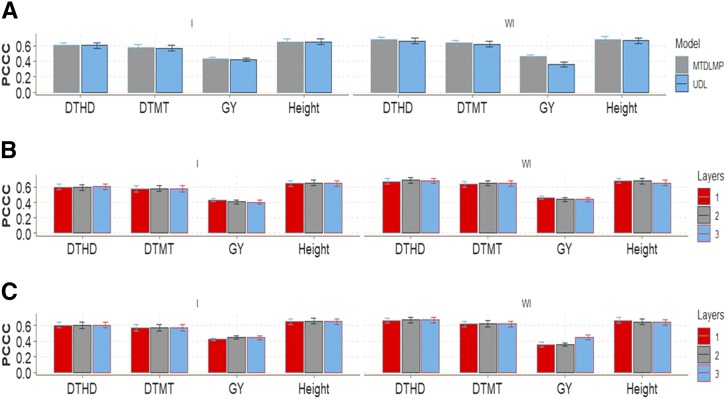
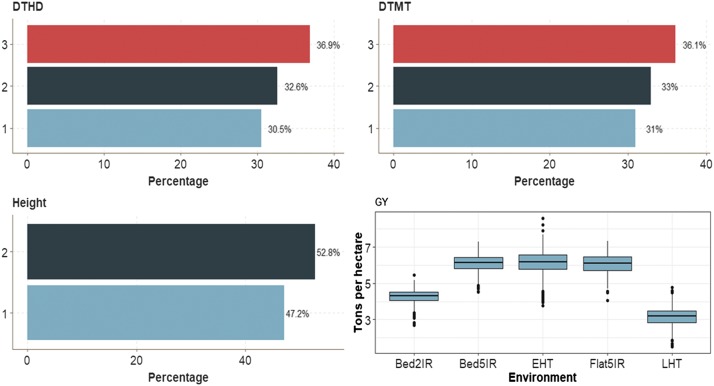
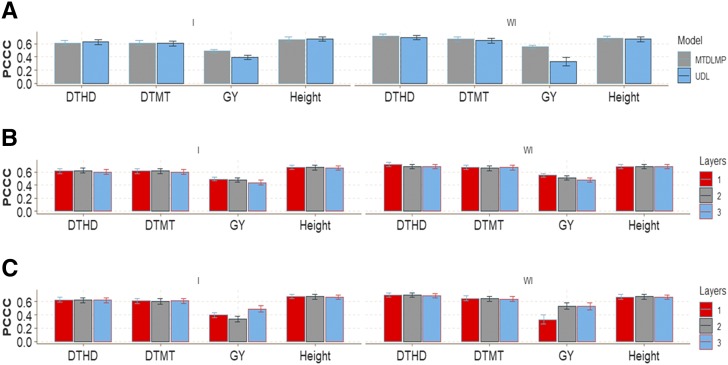
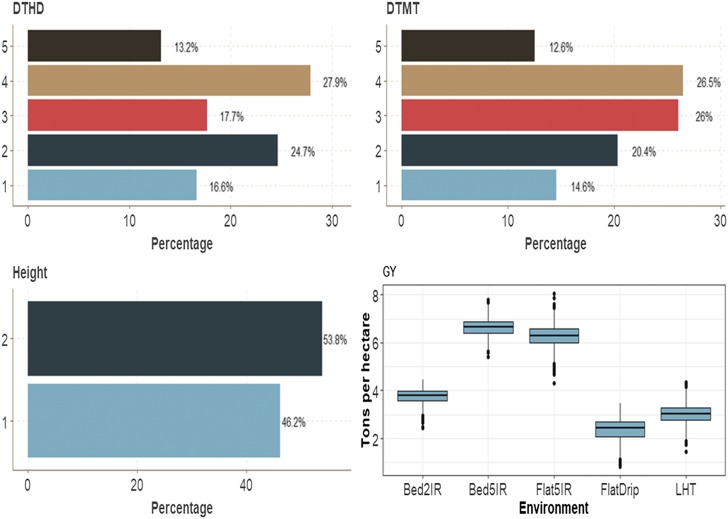
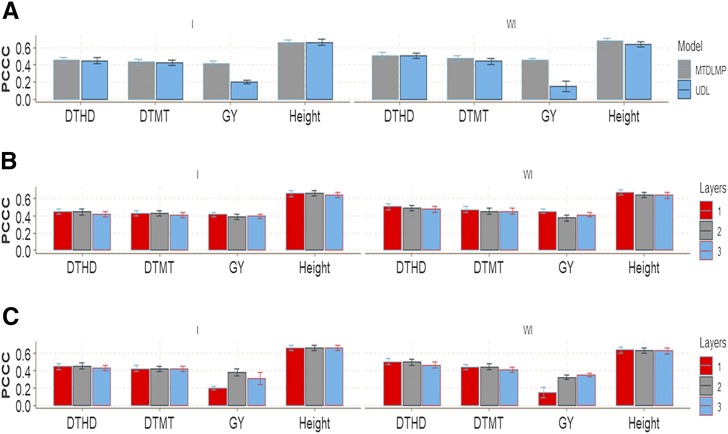
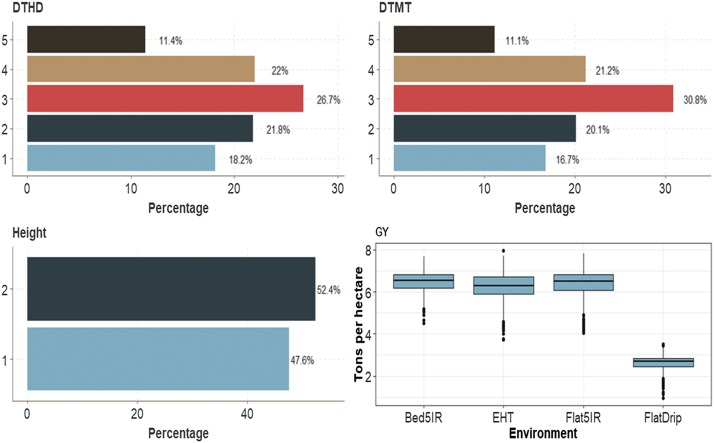
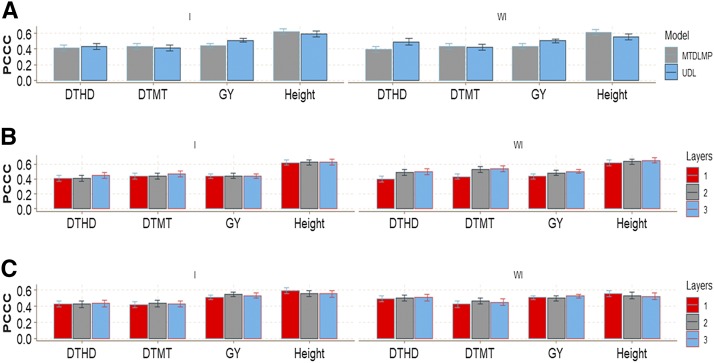
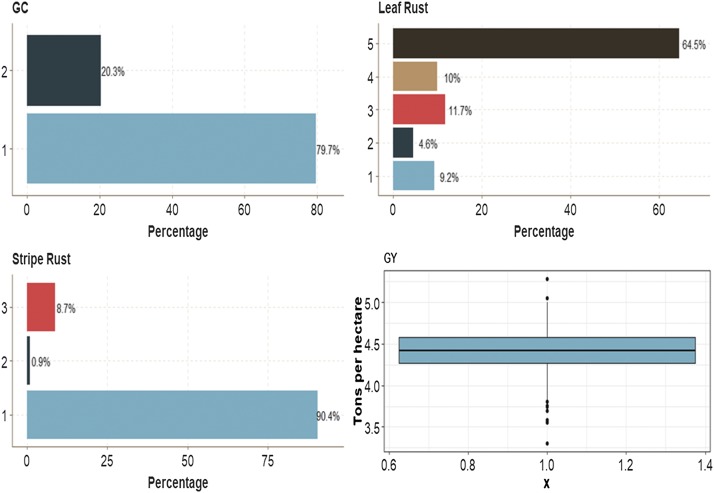
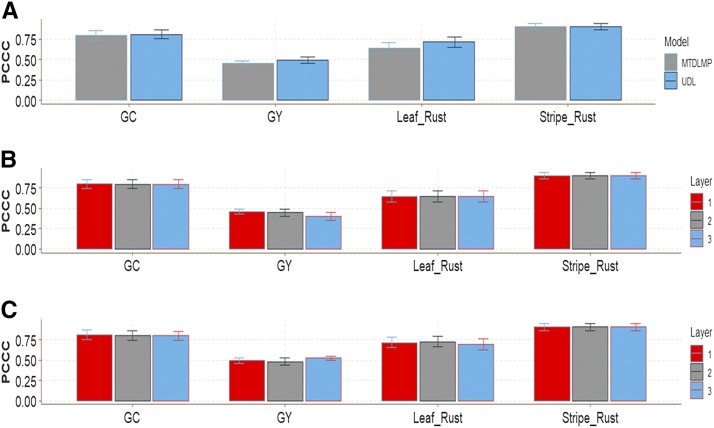
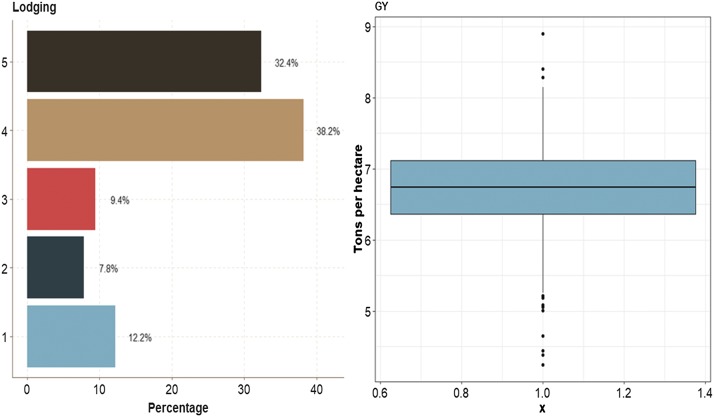
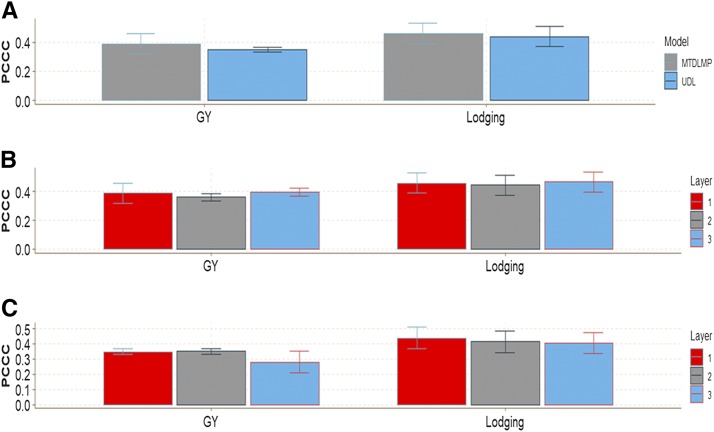
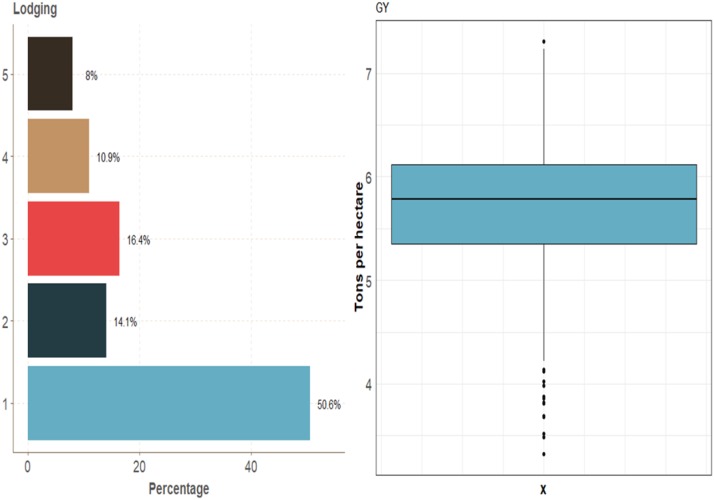
Multiple-trait experiments with mixed phenotypes (binary, ordinal and continuous) are not rare in animal and plant breeding programs. However, there is a lack of statistical models that can exploit the correlation between traits with mixed phenotypes in order to improve prediction accuracy in the context of genomic selection (GS). For this reason, when breeders have mixed phenotypes, they usually analyze them using univariate models, and thus are not able to exploit the correlation between traits, which many times helps improve prediction accuracy. In this paper we propose applying deep learning for analyzing multiple traits with mixed phenotype data in terms of prediction accuracy. The prediction performance of multiple-trait deep learning with mixed phenotypes (MTDLMP) models was compared to the performance of univariate deep learning (UDL) models. Both models were evaluated using predictors with and without the genotype × environment (G×E) interaction term (I and WI, respectively). The metric used for evaluating prediction accuracy was Pearson's correlation for continuous traits and the percentage of cases correctly classified (PCCC) for binary and ordinal traits. We found that a modest gain in prediction accuracy was obtained only in the continuous trait under the MTDLMP model compared to the UDL model, whereas for the other traits (1 binary and 2 ordinal) we did not find any difference between the two models. In both models we observed that the prediction performance was better for WI than for I. The MTDLMP model is a good alternative for performing simultaneous predictions of mixed phenotypes (binary, ordinal and continuous) in the context of GS.
多性状混合表型(二项式、有序和连续)实验在动植物育种计划中并不罕见。然而,缺乏能够利用混合表型性状之间相关性的统计模型,以便在基因组选择(GS)背景下提高预测准确性。出于这个原因,当饲养员有混合表型时,他们通常使用单变量模型对其进行分析,因此无法利用性状之间的相关性,而这种相关性通常有助于提高预测准确性。在本文中,我们提出应用深度学习来分析混合表型数据的多性状,以提高预测准确性。比较了多性状深度学习与混合表型模型(MTDLMP)和单变量深度学习(UDL)模型的预测性能。使用带有和不带有基因型×环境(G×E)互作项(I 和 WI,分别)的预测器来评估这两个模型。用于评估预测准确性的度量是连续性状的皮尔逊相关系数和二项式和有序性状的正确分类百分比(PCCC)。我们发现,与 UDL 模型相比,MTDLMP 模型仅在连续性状中获得了适度的预测准确性提高,而对于其他性状(1 个二项式和 2 个有序式),我们在两个模型之间没有发现任何差异。在这两个模型中,我们观察到 WI 的预测性能优于 I。MTDLMP 模型是在 GS 背景下同时进行混合表型(二项式、有序和连续)预测的一种很好的选择。