Ward Andrew, Sarraju Ashish, Chung Sukyung, Li Jiang, Harrington Robert, Heidenreich Paul, Palaniappan Latha, Scheinker David, Rodriguez Fatima
Department of Electrical Engineering, Stanford University, Stanford, CA USA.
Division of Cardiovascular Medicine, Stanford University School of Medicine, Stanford, CA USA.
NPJ Digit Med. 2020 Sep 23;3:125. doi: 10.1038/s41746-020-00331-1. eCollection 2020.
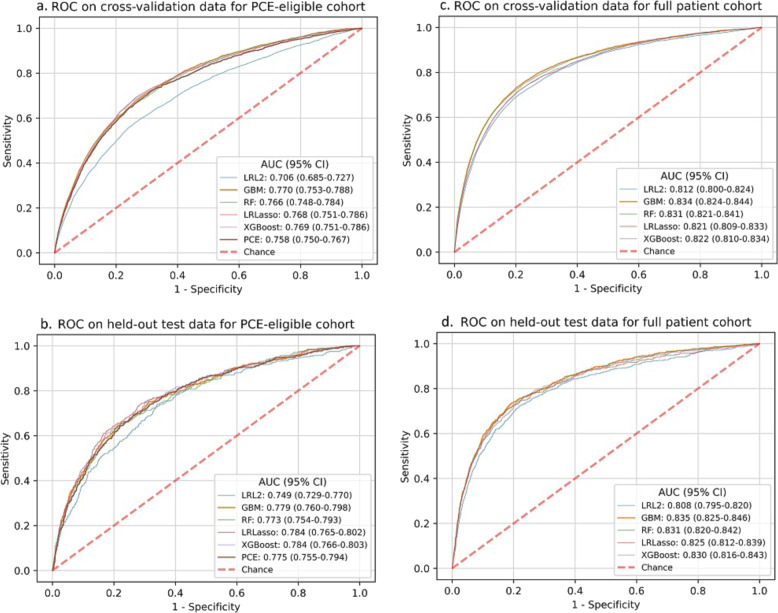
The pooled cohort equations (PCE) predict atherosclerotic cardiovascular disease (ASCVD) risk in patients with characteristics within prespecified ranges and has uncertain performance among Asians or Hispanics. It is unknown if machine learning (ML) models can improve ASCVD risk prediction across broader diverse, real-world populations. We developed ML models for ASCVD risk prediction for multi-ethnic patients using an electronic health record (EHR) database from Northern California. Our cohort included patients aged 18 years or older with no prior CVD and not on statins at baseline ( = 262,923), stratified by PCE-eligible ( = 131,721) or PCE-ineligible patients based on missing or out-of-range variables. We trained ML models [logistic regression with L penalty and L lasso penalty, random forest, gradient boosting machine (GBM), extreme gradient boosting] and determined 5-year ASCVD risk prediction, including with and without incorporation of additional EHR variables, and in Asian and Hispanic subgroups. A total of 4309 patients had ASCVD events, with 2077 in PCE-ineligible patients. GBM performance in the full cohort, including PCE-ineligible patients (area under receiver-operating characteristic curve (AUC) 0.835, 95% confidence interval (CI): 0.825-0.846), was significantly better than that of the PCE in the PCE-eligible cohort (AUC 0.775, 95% CI: 0.755-0.794). Among patients aged 40-79, GBM performed similarly before (AUC 0.784, 95% CI: 0.759-0.808) and after (AUC 0.790, 95% CI: 0.765-0.814) incorporating additional EHR data. Overall, ML models achieved comparable or improved performance compared to the PCE while allowing risk discrimination in a larger group of patients including PCE-ineligible patients. EHR-trained ML models may help bridge important gaps in ASCVD risk prediction.
汇总队列方程(PCE)可预测具有预先指定范围内特征的患者的动脉粥样硬化性心血管疾病(ASCVD)风险,但其在亚洲人或西班牙裔人群中的表现尚不确定。机器学习(ML)模型能否在更广泛的不同现实世界人群中改善ASCVD风险预测尚不清楚。我们使用北加利福尼亚州的电子健康记录(EHR)数据库开发了用于多民族患者ASCVD风险预测的ML模型。我们的队列包括18岁及以上、基线时无既往心血管疾病且未服用他汀类药物的患者(n = 262,923),根据缺失或超出范围的变量分为符合PCE标准的患者(n = 131,721)或不符合PCE标准的患者。我们训练了ML模型[带L1惩罚和L2套索惩罚的逻辑回归、随机森林、梯度提升机(GBM)、极端梯度提升],并确定了5年ASCVD风险预测,包括纳入和不纳入额外EHR变量的情况,以及在亚洲和西班牙裔亚组中的情况。共有4309例患者发生ASCVD事件,其中2077例发生在不符合PCE标准的患者中。在整个队列(包括不符合PCE标准的患者)中,GBM的表现(受试者操作特征曲线下面积(AUC)为0.835,95%置信区间(CI):0.825 - 0.846)显著优于符合PCE标准队列中的PCE(AUC为0.775,95%CI:0.755 - 0.794)。在40 - 79岁的患者中,纳入额外EHR数据之前(AUC为0.784,95%CI:0.759 - 0.808)和之后(AUC为0.790,95%CI:0.765 - 0.814),GBM的表现相似。总体而言,与PCE相比,ML模型实现了相当或更好的表现,同时能够在包括不符合PCE标准的患者在内的更大患者群体中进行风险区分。经EHR训练的ML模型可能有助于弥合ASCVD风险预测中的重要差距。