Guleria Pratiyush, Sood Manu
National Institute of Electronics and Information Technology (NIELIT), Shimla, Himachal Pradesh India.
Department of Computer Science, Himachal Pradesh University, Shimla, Himachal Pradesh India.
Educ Inf Technol (Dordr). 2023;28(1):1081-1116. doi: 10.1007/s10639-022-11221-2. Epub 2022 Jul 16.
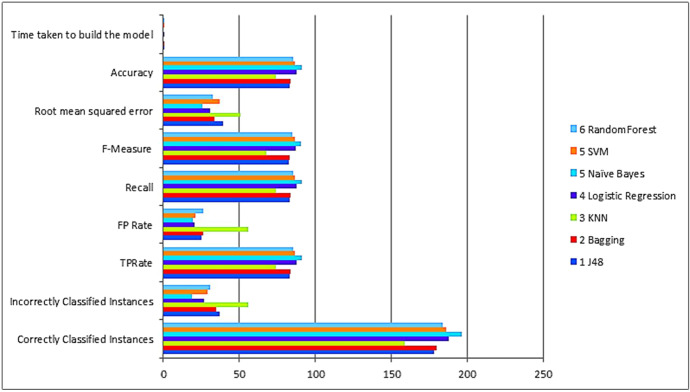
Machine Learning concept learns from experiences, inferences and conceives complex queries. Machine learning techniques can be used to develop the educational framework which understands the inputs from students, parents and with intelligence generates the result. The framework integrates the features of Machine Learning (ML), Explainable AI (XAI) to analyze the educational factors which are helpful to students in achieving career placements and help students to opt for the right decision for their career growth. It is supposed to work like an expert system with decision support to figure out the problems, the way humans solve the problems by understanding, analyzing, and remembering. In this paper, the authors have proposed a framework for career counseling of students using ML and AI techniques. ML-based White and Black Box models analyze the educational dataset comprising of academic and employability attributes that are important for the job placements and skilling of the students. In the proposed framework, White Box and Black Box models get trained over an educational dataset taken in the study. The Recall and F-Measure score achieved by the Naive Bayes for performing predictions is 91.2% and 90.7% that is best compared to the score of Logistic Regression, Decision Tree, SVM, KNN, and Ensemble models taken in the study.
机器学习概念从经验和推理中学习,并构思复杂的查询。机器学习技术可用于开发教育框架,该框架能理解来自学生、家长的输入,并智能地生成结果。该框架整合了机器学习(ML)、可解释人工智能(XAI)的特性,以分析有助于学生实现职业安置的教育因素,并帮助学生为其职业发展做出正确决策。它应该像一个具有决策支持功能的专家系统一样工作,通过理解、分析和记忆来找出问题,就像人类解决问题的方式一样。在本文中,作者提出了一个使用ML和AI技术为学生进行职业咨询的框架。基于ML的白盒和黑盒模型分析了包含学术和就业能力属性的教育数据集,这些属性对学生的就业安置和技能培养很重要。在所提出的框架中,白盒和黑盒模型在研究中采用的教育数据集上进行训练。朴素贝叶斯进行预测所获得的召回率和F值分数分别为91.2%和90.7%,与研究中采用的逻辑回归、决策树、支持向量机(SVM)、K近邻(KNN)和集成模型的分数相比是最好的。