Li Tianhao, Shetty Sandesh, Kamath Advaith, Jaiswal Ajay, Jiang Xiaoqian, Ding Ying, Kim Yejin
School of Information, University of Texas at Austin, Austin, TX, USA.
Manning College of Information and Computer Sciences, University of Massachusetts Amherst, Amherst, MA, USA.
NPJ Digit Med. 2024 Feb 19;7(1):40. doi: 10.1038/s41746-024-01024-9.
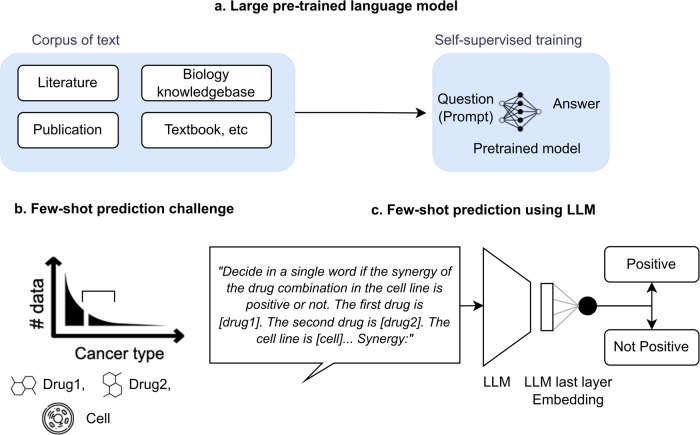
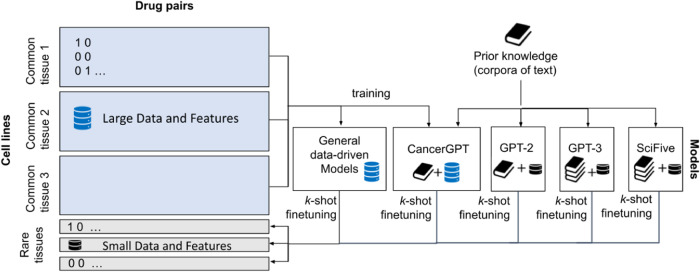
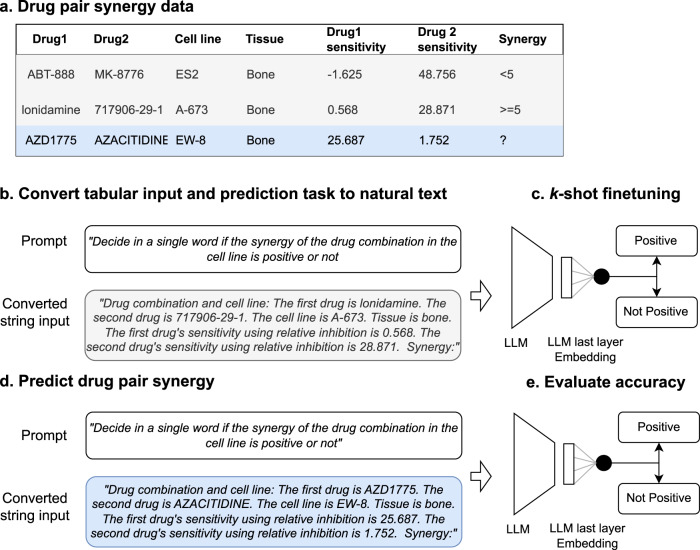
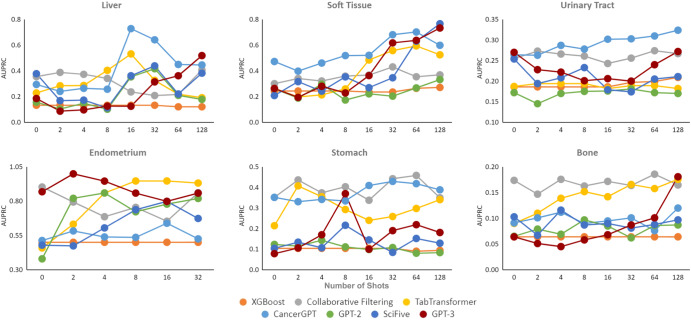
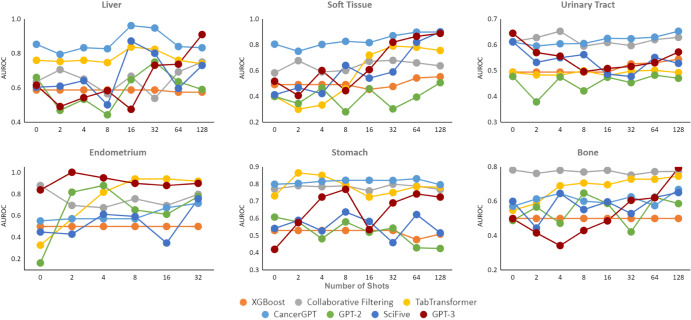
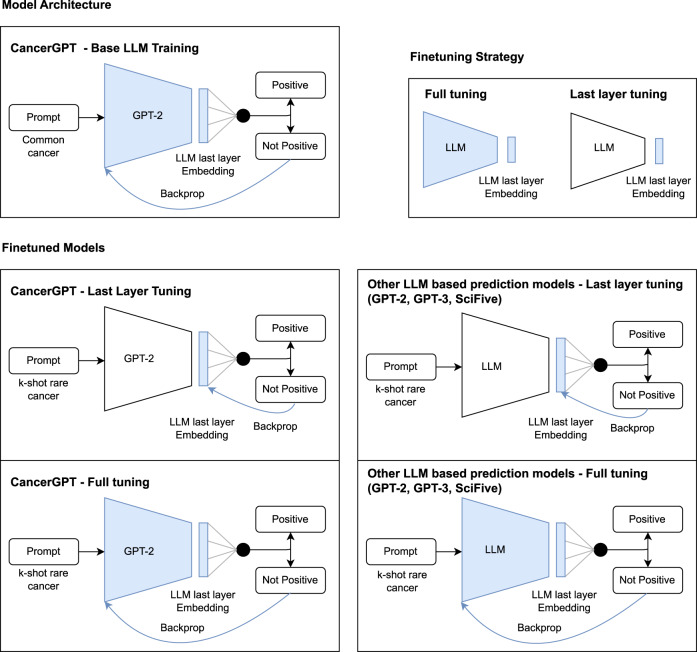
Large language models (LLMs) have been shown to have significant potential in few-shot learning across various fields, even with minimal training data. However, their ability to generalize to unseen tasks in more complex fields, such as biology and medicine has yet to be fully evaluated. LLMs can offer a promising alternative approach for biological inference, particularly in cases where structured data and sample size are limited, by extracting prior knowledge from text corpora. Here we report our proposed few-shot learning approach, which uses LLMs to predict the synergy of drug pairs in rare tissues that lack structured data and features. Our experiments, which involved seven rare tissues from different cancer types, demonstrate that the LLM-based prediction model achieves significant accuracy with very few or zero samples. Our proposed model, the CancerGPT (with ~ 124M parameters), is comparable to the larger fine-tuned GPT-3 model (with ~ 175B parameters). Our research contributes to tackling drug pair synergy prediction in rare tissues with limited data, and also advancing the use of LLMs for biological and medical inference tasks.
大语言模型(LLMs)已被证明在跨领域的少样本学习中具有巨大潜力,即使训练数据极少。然而,它们在更复杂领域(如生物学和医学)中推广到未见任务的能力尚未得到充分评估。大语言模型可以通过从文本语料库中提取先验知识,为生物推理提供一种有前景的替代方法,特别是在结构化数据和样本量有限的情况下。在此,我们报告我们提出的少样本学习方法,该方法使用大语言模型来预测缺乏结构化数据和特征的罕见组织中药物对的协同作用。我们的实验涉及来自不同癌症类型的七种罕见组织,结果表明基于大语言模型的预测模型在极少样本或零样本的情况下就能达到显著的准确率。我们提出的模型CancerGPT(约1.24亿个参数)与更大的微调GPT-3模型(约1750亿个参数)相当。我们的研究有助于解决数据有限的罕见组织中的药物对协同作用预测问题,也推动了大语言模型在生物和医学推理任务中的应用。