Korea Advanced Institute of Science and Technology (KAIST), Daejeon, South Korea.
Asan Medical Center, University of Ulsan College of Medicine, Seoul, South Korea.
Med Image Anal. 2022 Jan;75:102299. doi: 10.1016/j.media.2021.102299. Epub 2021 Nov 4.
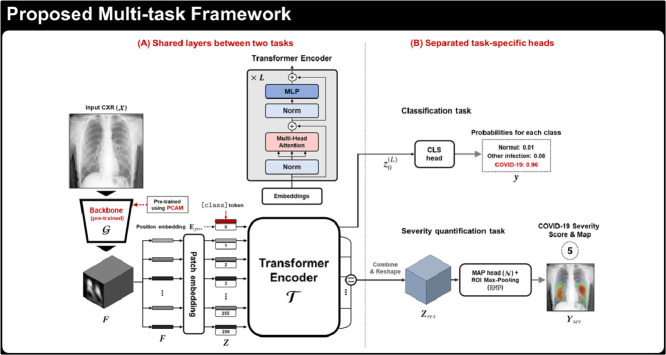
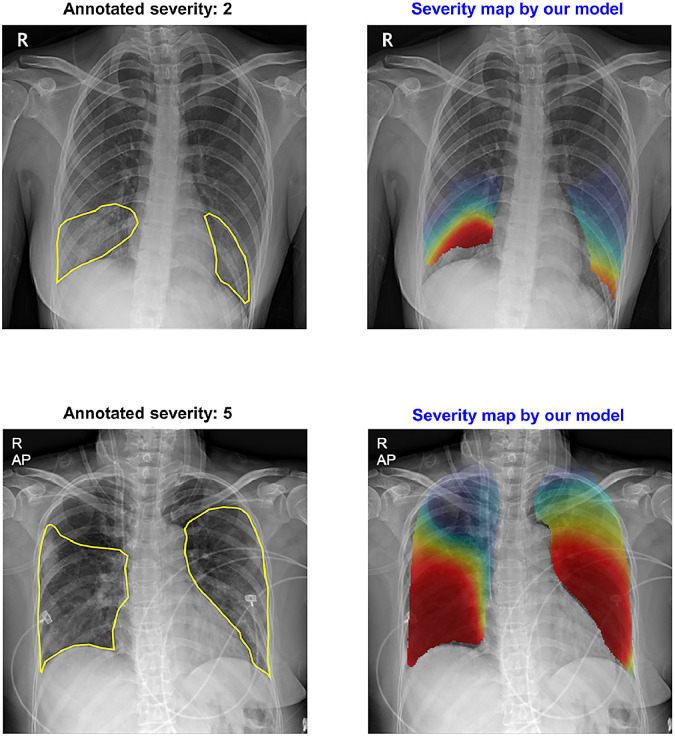
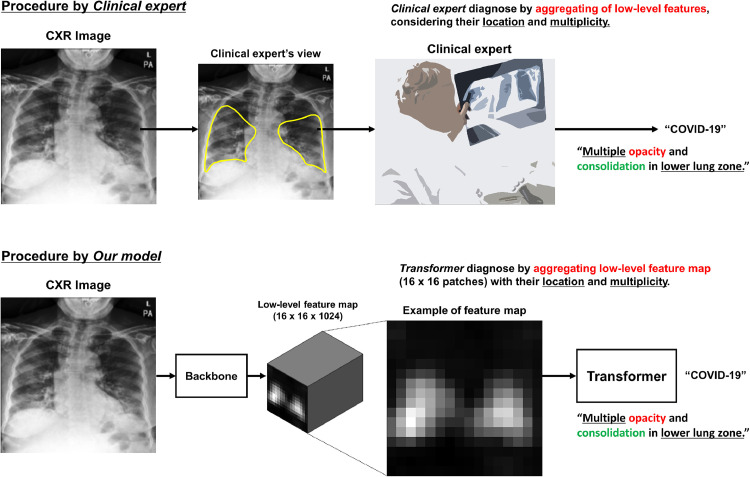
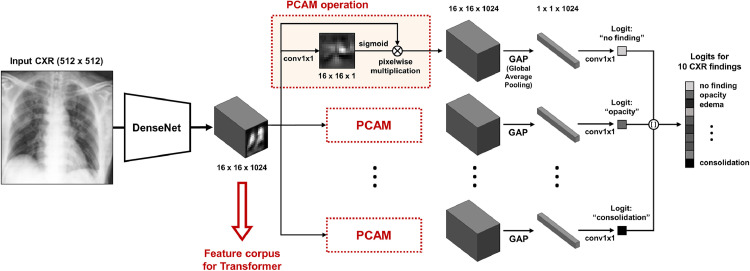
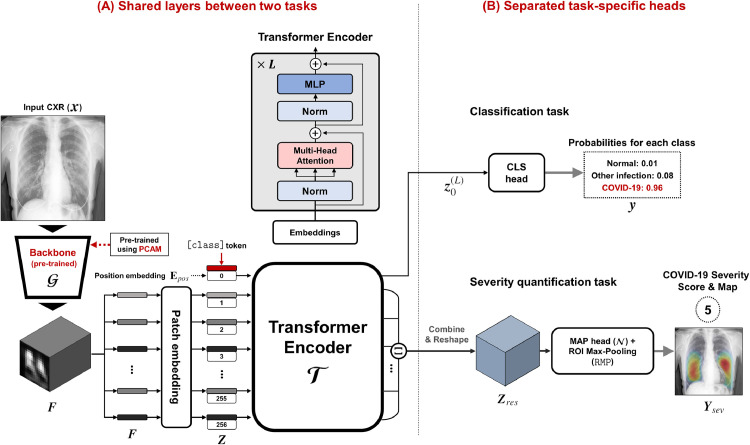
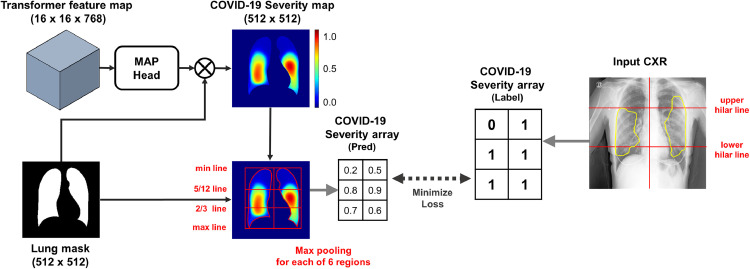
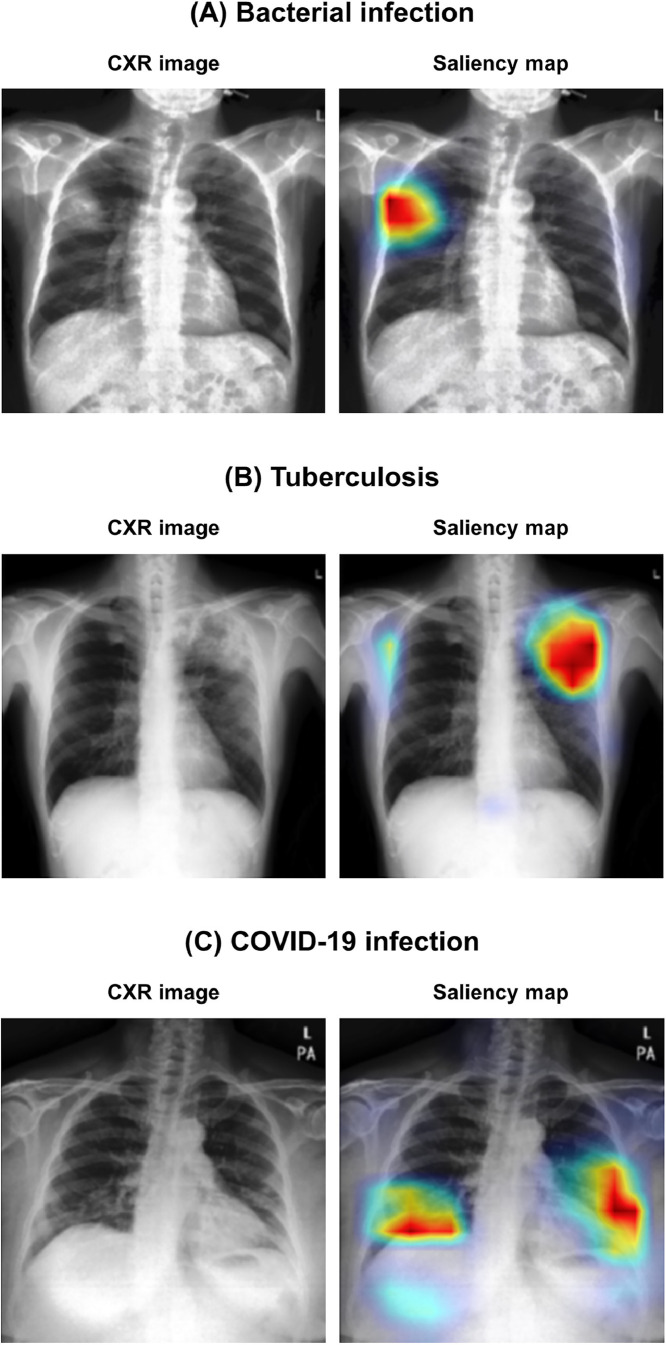
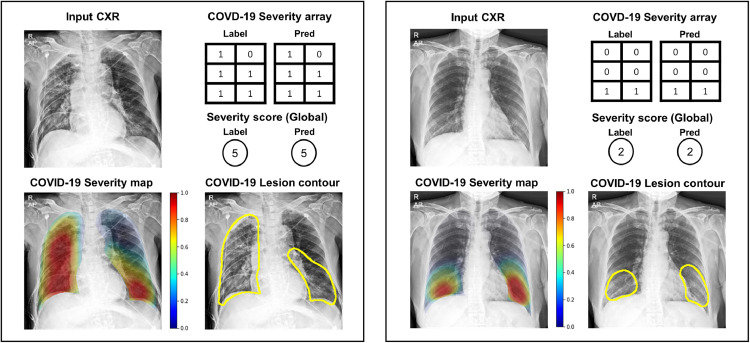
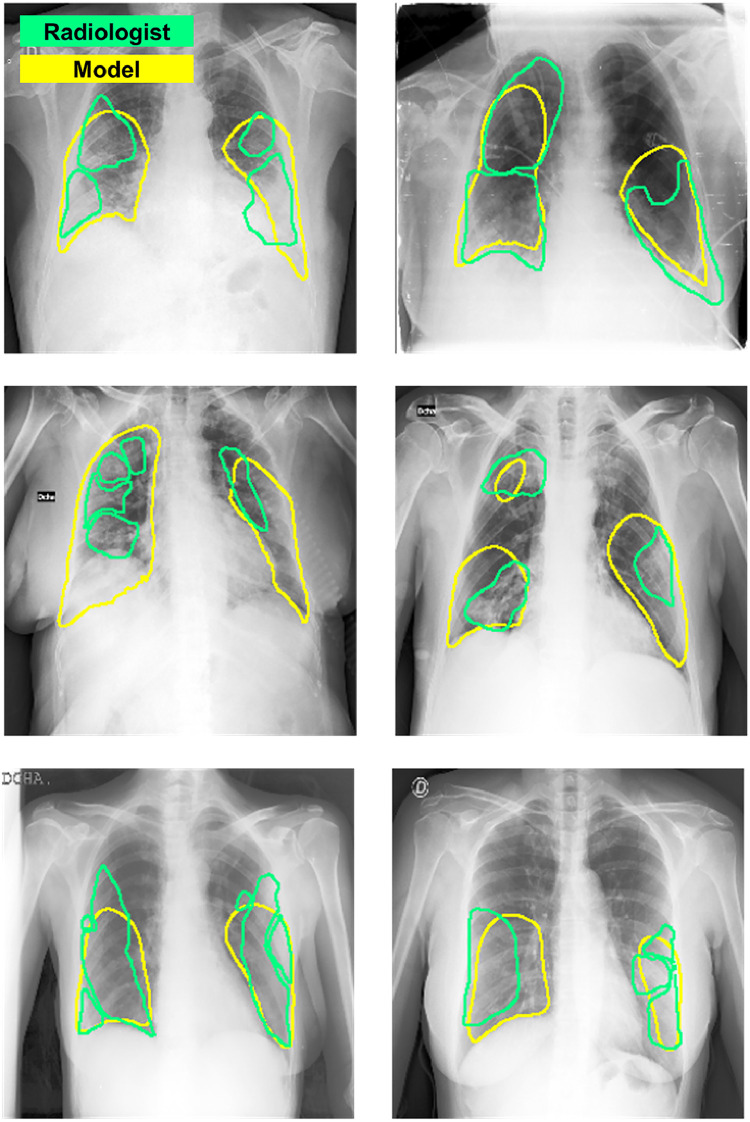
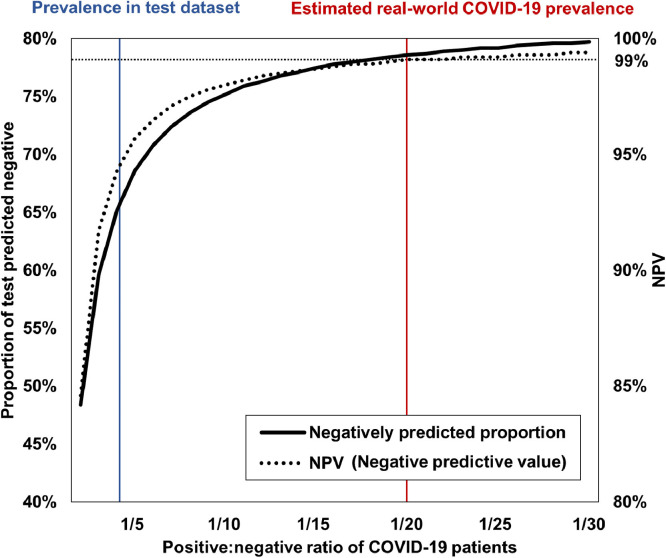
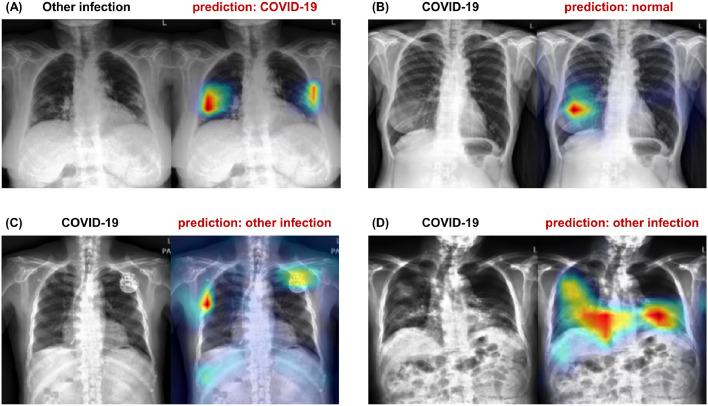
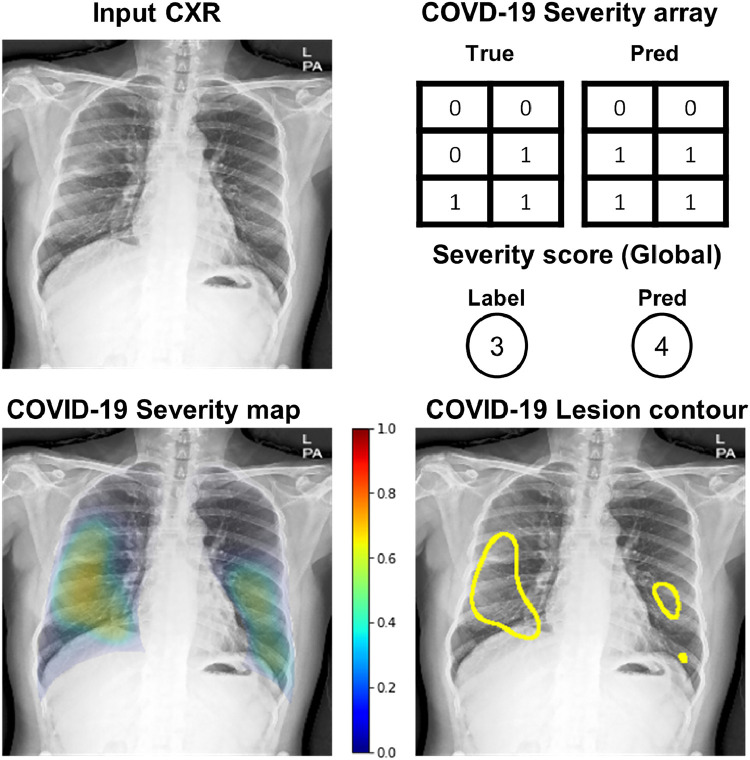
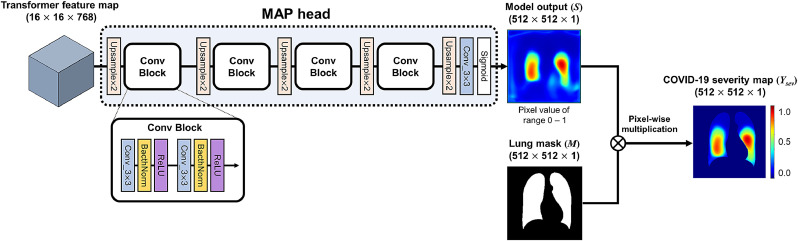
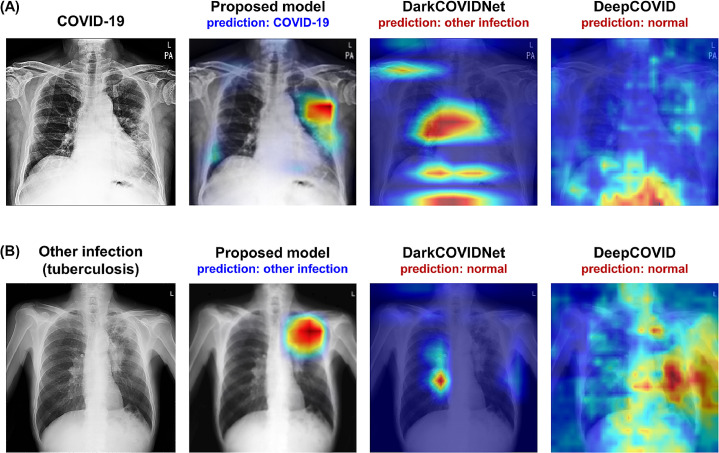
Developing a robust algorithm to diagnose and quantify the severity of the novel coronavirus disease 2019 (COVID-19) using Chest X-ray (CXR) requires a large number of well-curated COVID-19 datasets, which is difficult to collect under the global COVID-19 pandemic. On the other hand, CXR data with other findings are abundant. This situation is ideally suited for the Vision Transformer (ViT) architecture, where a lot of unlabeled data can be used through structural modeling by the self-attention mechanism. However, the use of existing ViT may not be optimal, as the feature embedding by direct patch flattening or ResNet backbone in the standard ViT is not intended for CXR. To address this problem, here we propose a novel Multi-task ViT that leverages low-level CXR feature corpus obtained from a backbone network that extracts common CXR findings. Specifically, the backbone network is first trained with large public datasets to detect common abnormal findings such as consolidation, opacity, edema, etc. Then, the embedded features from the backbone network are used as corpora for a versatile Transformer model for both the diagnosis and the severity quantification of COVID-19. We evaluate our model on various external test datasets from totally different institutions to evaluate the generalization capability. The experimental results confirm that our model can achieve state-of-the-art performance in both diagnosis and severity quantification tasks with outstanding generalization capability, which are sine qua non of widespread deployment.
开发一种强大的算法,使用胸部 X 光(CXR)诊断和量化新型冠状病毒病 2019(COVID-19)的严重程度,需要大量精心整理的 COVID-19 数据集,但在全球 COVID-19 大流行下,这很难收集到。另一方面,带有其他发现的 CXR 数据却很丰富。这种情况非常适合 Vision Transformer(ViT)架构,通过自注意力机制的结构建模,可以使用大量未标记的数据。然而,使用现有的 ViT 可能不是最佳选择,因为标准 ViT 中的直接补丁展平和 ResNet 骨干中的特征嵌入并不适用于 CXR。为了解决这个问题,我们在这里提出了一种新的多任务 ViT,它利用了从骨干网络提取的常见 CXR 发现的低级 CXR 特征语料库。具体来说,骨干网络首先使用大型公共数据集进行训练,以检测常见的异常发现,如实变、不透明、水肿等。然后,骨干网络的嵌入式特征被用作多功能 Transformer 模型的语料库,用于 COVID-19 的诊断和严重程度量化。我们在来自不同机构的各种外部测试数据集上评估我们的模型,以评估其泛化能力。实验结果证实,我们的模型在诊断和严重程度量化任务中都可以达到最先进的性能,并具有出色的泛化能力,这是广泛部署的必要条件。