Department of Biomedical Engineering, National Defense Medical Center, Taipei, 114, Taiwan, ROC.
Graduate Institute of Applied Science and Technology, National Taiwan University of Science and Technology, Taipei, 106, Taiwan, ROC.
BMC Bioinformatics. 2021 Nov 8;22(Suppl 5):84. doi: 10.1186/s12859-021-04005-x.
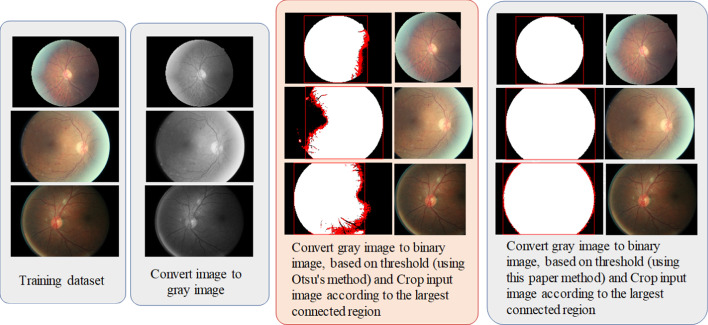
Doctors can detect symptoms of diabetic retinopathy (DR) early by using retinal ophthalmoscopy, and they can improve diagnostic efficiency with the assistance of deep learning to select treatments and support personnel workflow. Conventionally, most deep learning methods for DR diagnosis categorize retinal ophthalmoscopy images into training and validation data sets according to the 80/20 rule, and they use the synthetic minority oversampling technique (SMOTE) in data processing (e.g., rotating, scaling, and translating training images) to increase the number of training samples. Oversampling training may lead to overfitting of the training model. Therefore, untrained or unverified images can yield erroneous predictions. Although the accuracy of prediction results is 90%-99%, this overfitting of training data may distort training module variables.
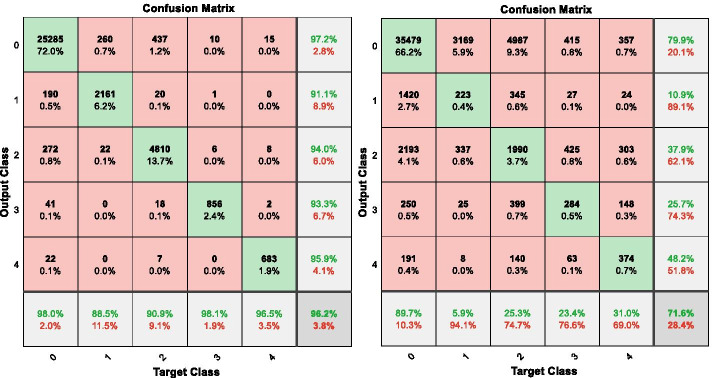
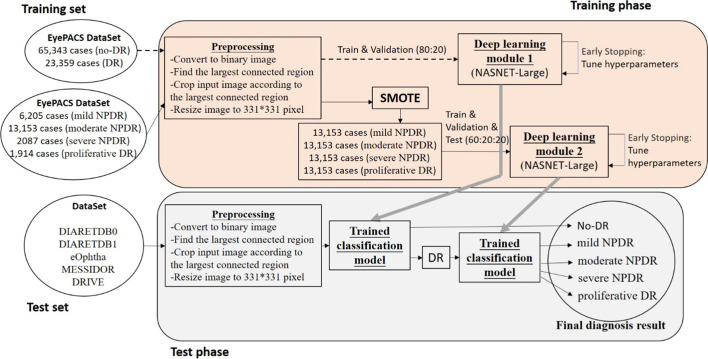
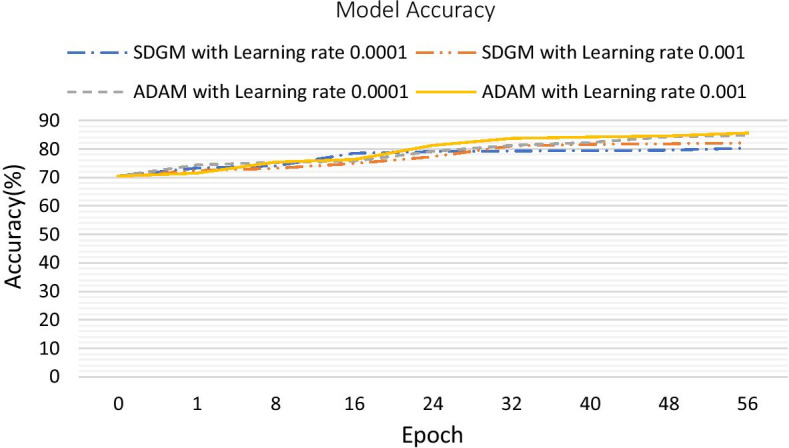
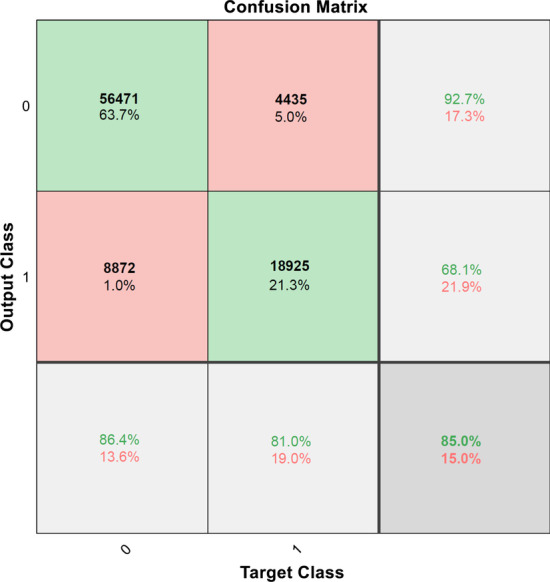
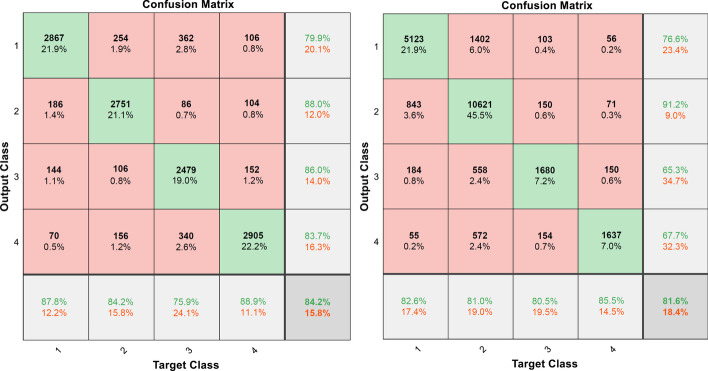
This study uses a 2-stage training method to solve the overfitting problem. In the training phase, to build the model, the Learning module 1 used to identify the DR and no-DR. The Learning module 2 on SMOTE synthetic datasets to identify the mild-NPDR, moderate NPDR, severe NPDR and proliferative DR classification. These two modules also used early stopping and data dividing methods to reduce overfitting by oversampling. In the test phase, we use the DIARETDB0, DIARETDB1, eOphtha, MESSIDOR, and DRIVE datasets to evaluate the performance of the training network. The prediction accuracy achieved to 85.38%, 84.27%, 85.75%, 86.73%, and 92.5%.
Based on the experiment, a general deep learning model for detecting DR was developed, and it could be used with all DR databases. We provided a simple method of addressing the imbalance of DR databases, and this method can be used with other medical images.
医生可以通过视网膜检眼镜早期发现糖尿病视网膜病变(DR)的症状,并借助深度学习选择治疗方法和辅助人员的工作流程,提高诊断效率。传统上,DR 诊断的大多数深度学习方法根据 80/20 规则将视网膜检眼镜图像分为训练集和验证集,并在数据处理(例如旋转、缩放和翻译训练图像)中使用合成少数过采样技术(SMOTE)来增加训练样本的数量。过采样训练可能导致训练模型过度拟合。因此,未经训练或未经验证的图像可能会产生错误的预测。尽管预测结果的准确率在 90%-99%之间,但这种对训练数据的过度拟合可能会扭曲训练模块变量。
本研究使用两阶段训练方法来解决过拟合问题。在训练阶段,为了构建模型,学习模块 1 用于识别 DR 和非 DR。学习模块 2 用于在 SMOTE 合成数据集上识别轻度 NPDR、中度 NPDR、重度 NPDR 和增生性 DR 分类。这两个模块还使用提前停止和数据划分方法来减少过采样的过度拟合。在测试阶段,我们使用 DIARETDB0、DIARETDB1、eOphtha、MESSIDOR 和 DRIVE 数据集来评估训练网络的性能。预测准确率达到 85.38%、84.27%、85.75%、86.73%和 92.5%。
基于实验,开发了一种用于检测 DR 的通用深度学习模型,可用于所有 DR 数据库。我们提供了一种解决 DR 数据库不平衡问题的简单方法,该方法可用于其他医学图像。